Neurons in LLMs: Dead, N-gram, Positional
This is a post for the paper Neurons in Large Language Models: Dead, N-gram, Positional.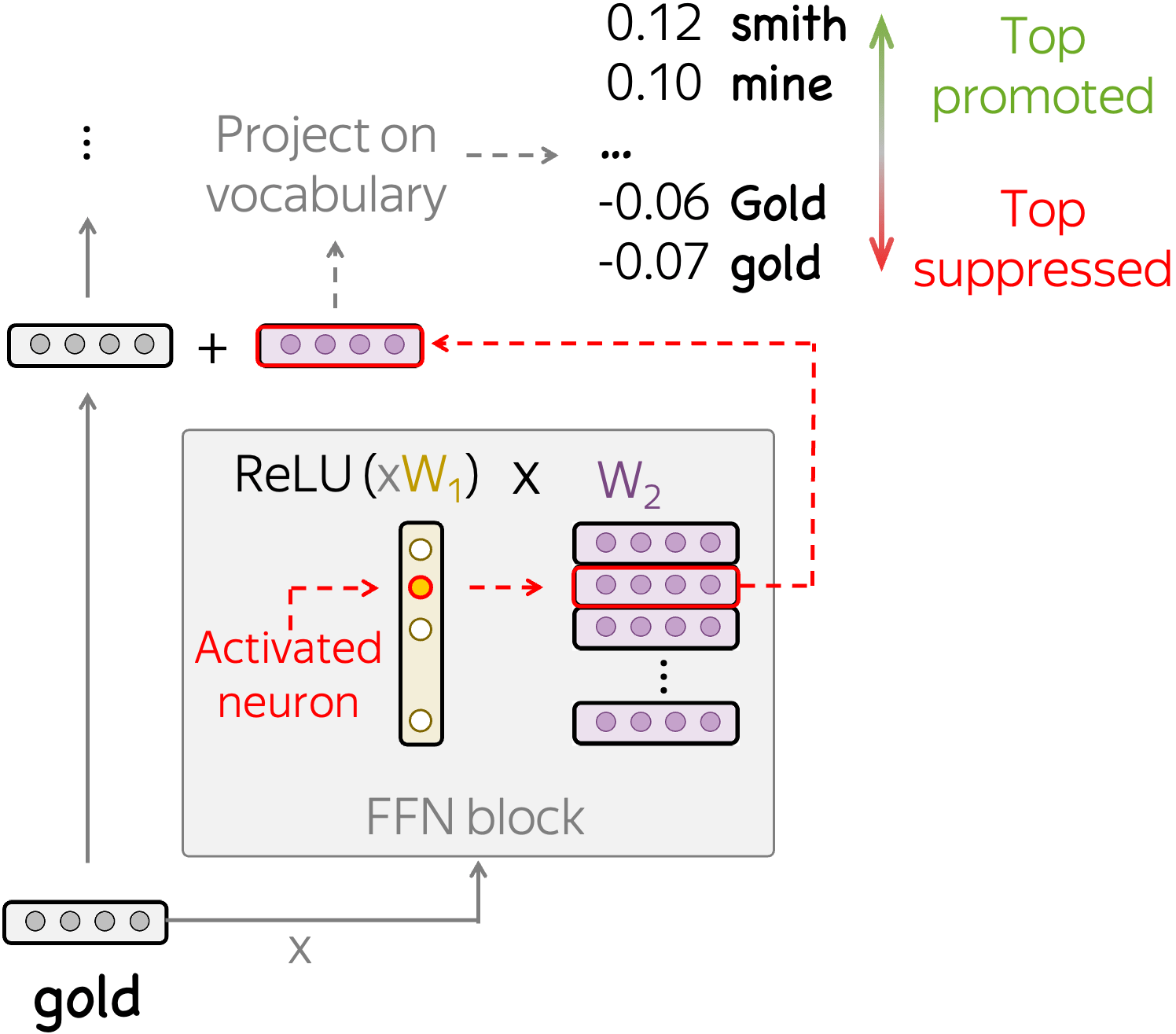
With scale, LMs become more exciting but, at the same time, harder to analyze. We show that even with simple methods and a single GPU, you can do a lot! We analyze OPT models up to 66b and find that
- neurons inside LLMs can be:
- dead, i.e. never activate on a large dataset,
- n-gram detectors that explicitly remove information about current input token;
- positional, i.e. encode "where" regardless of "what" and question the key-value memory view of FFNs;
- with scale, models have more dead neurons and token detectors and are less focused on absolute position.
 September 2023
September 2023
NMT Training Process though the Lens of SMT
This is a post for the EMNLP 2021 paper Language Modeling, Lexical Translation, Reordering: The Training Process of NMT through the Lens of Classical SMT.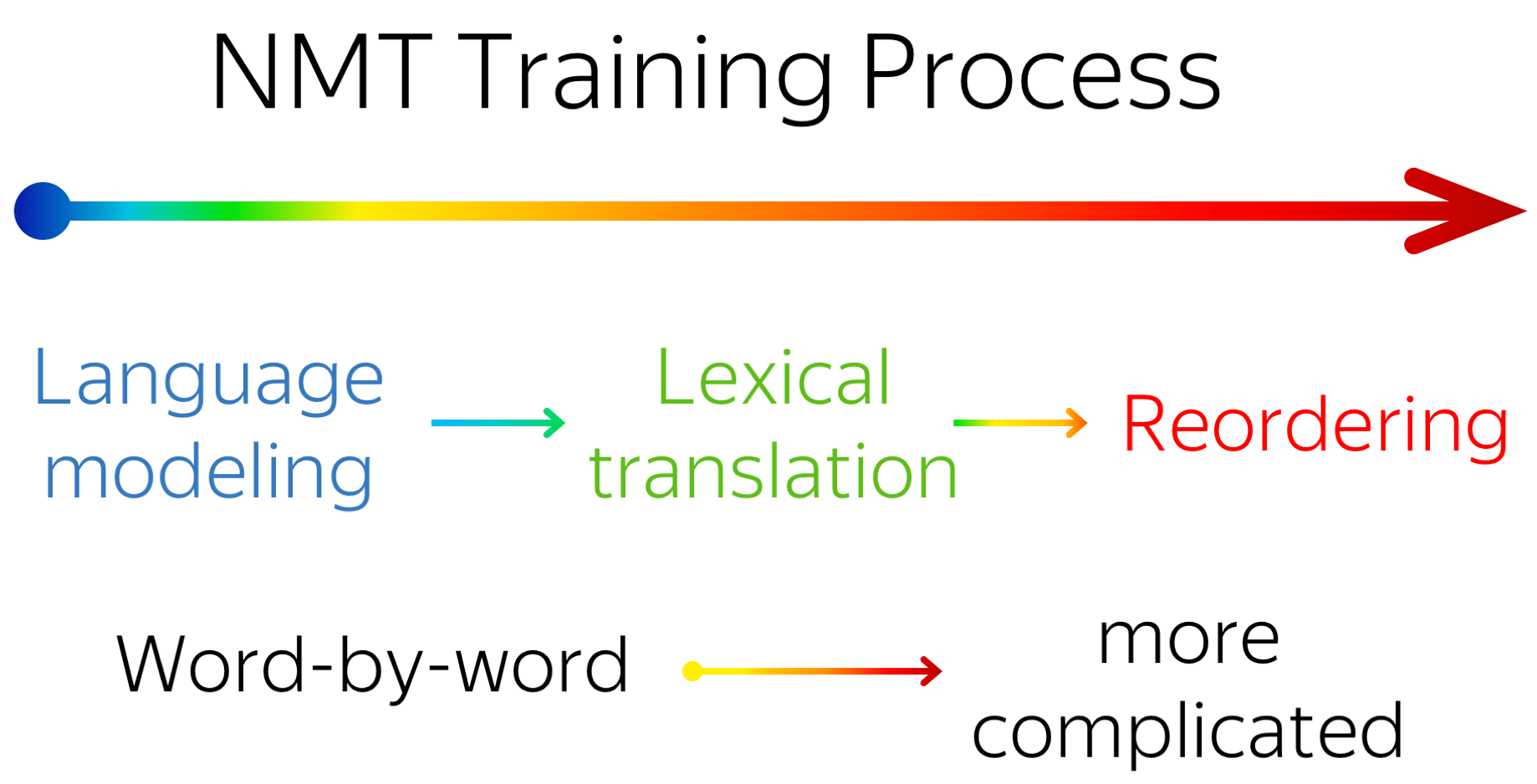
In SMT, model competences are modelled with distinct models. In NMT, the whole translation task is modelled with a single neural network. How and when does NMT get to learn all the competences? We show that
- during training, NMT undergoes three different stages:
- target-side language modeling,
- learning how to use source and approaching word-by-word translation,
- refining translations, visible by increasingly complex reorderings but not visible by e.g. BLEU;
- not only this is fun, but it can also help in practice! For example, in settings where data complexity matters, such as non-autoregressive NMT.
September 2021
Neural Machine Translation Inside Out
 This is a blog version of my talk at the ACL 2021 workshop
Representation
Learning for NLP (and an updated version
of that at NAACL 2021 workshop
Deep Learning Inside Out (DeeLIO)).
This is a blog version of my talk at the ACL 2021 workshop
Representation
Learning for NLP (and an updated version
of that at NAACL 2021 workshop
Deep Learning Inside Out (DeeLIO)).
In the last decade, machine translation shifted from the traditional statistical approaches with distinct components and hand-crafted features to the end-to-end neural ones. We try to understand how NMT works and show that:
- NMT model components can learn to extract features which in SMT were modelled explicitly;
- for NMT, we can also look at how it balances the two different types of context: the source and the prefix;
- NMT training consists of the stages where it focuses on competences mirroring three core SMT components.
July 2021
Source and Target Contributions to NMT Predictions
This is a post for the ACL 2021 paper Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation.In NMT, the generation of a target token is based on two types of context: the source and the prefix of the target sentence. We show how to evaluate the relative contributions of source and target to NMT predictions and find that:
- models suffering from exposure bias are more prone to over-relying on target history (and hence to hallucinating) than the ones where the exposure bias is mitigated;
- models trained with more data rely on the source more and do it more confidently;
- the training process is non-monotonic with several distinct stages.
 October 2020
October 2020
Information-Theoretic Probing with MDL
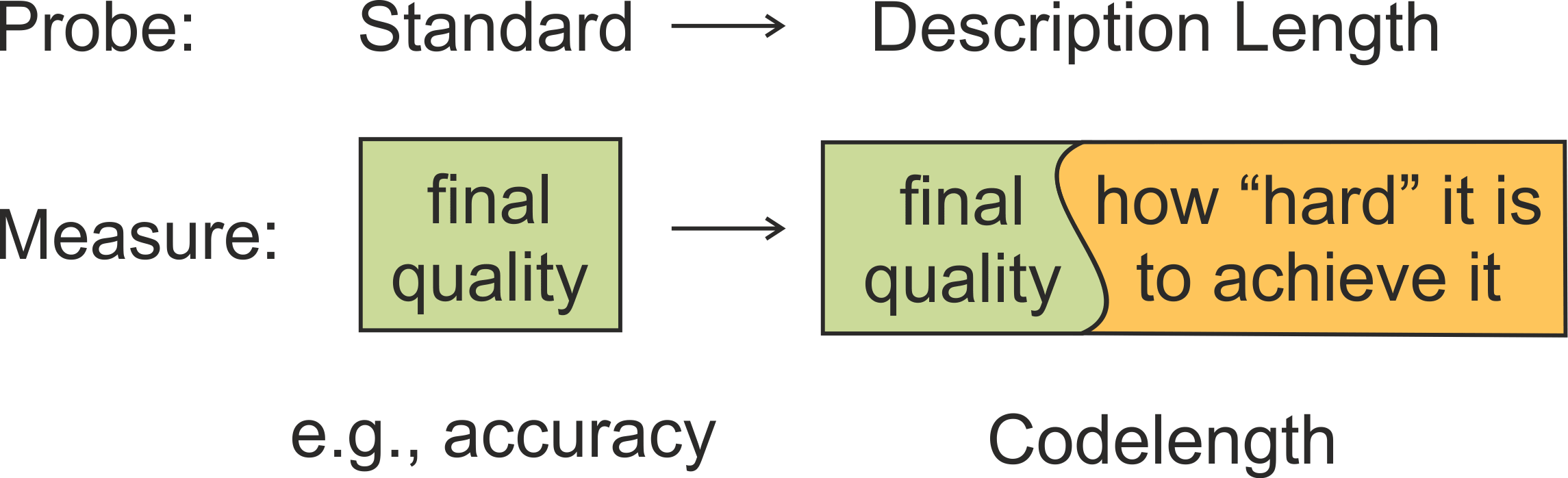 This is a post for the EMNLP 2020 paper
Information-Theoretic Probing with Minimum Description Length.
This is a post for the EMNLP 2020 paper
Information-Theoretic Probing with Minimum Description Length.
Probing classifiers often fail to adequately reflect differences in representations and can show different results depending on hyperparameters. As an alternative to the standard probes,
- we propose information-theoretic probing which measures minimum description length (MDL) of labels given representations;
- we show that MDL characterizes both probe quality and the amount of effort needed to achieve it;
- we explain how to easily measure MDL on top of standard probe-training pipelines;
- we show that results of MDL probes are more informative and stable than those of standard probes.
March 2020
Evolution of Representations in the Transformer
We look at the evolution of representations of individual tokens in Transformers trained with different training objectives (MT, LM, MLM - BERT-style) from the Information Bottleneck perspective and show, that:
- LMs gradually forget past when forming predictions about future;
- for MLMs, the evolution proceeds in two stages of context encoding and token reconstruction;
- MT representations get refined with context, but less processing is happening.
September 2019
When a Good Translation is Wrong in Context
This is a post for the ACL 2019 paper When a Good Translation is Wrong in Context: Context-Aware Machine Translation Improves on Deixis, Ellipsis, and Lexical Cohesion.From this post, you will learn:
- which phenomena cause context-agnostic translations to be inconsistent with each other
- how we create test sets addressing the most frequent phenomena
- about a novel set-up for context-aware NMT with a large amount of sentence-level data and much less of document-level data
- about a new model for this set-up (Context-Aware Decoder, aka CADec) - a two-pass MT model which first produces a draft translation of the current sentence, then corrects it using context.
July 2019
The Story of Heads
 This is a post for the ACL 2019 paper
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned.
This is a post for the ACL 2019 paper
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned.
From this post, you will learn:
- how we evaluate the importance of attention heads in Transformer
- which functions the most important encoder heads perform
- how we prune the vast majority of attention heads in Transformer without seriously affecting quality
- which types of model attention are most sensitive to the number of attention heads and on which layers
June 2019