When a Good Translation is Wrong in Context
From this post, you will learn:
- which phenomena cause context-agnostic translations to be inconsistent with each other
- how we create test sets addressing the most frequent phenomena
- about a novel set-up for context-aware NMT with a large amount of sentence-level data and much less of document-level data
- about a new model for this set-up (Context-Aware Decoder, aka CADec) - a two-pass MT model which first produces a draft translation of the current sentence, then corrects it using context.
 July 2019
July 2019
Human Annotation and Analysis
 Why do we need context-aware MT?
Why do we need context-aware MT? To translate a document, one can split it into sentences, translate them independently and put the translations together to form a translation of a document. That's right! We would be ok with such approach if translations of isolated sentences put together formed a meaningful and coherent text. Unfortunately, often this is not the case.
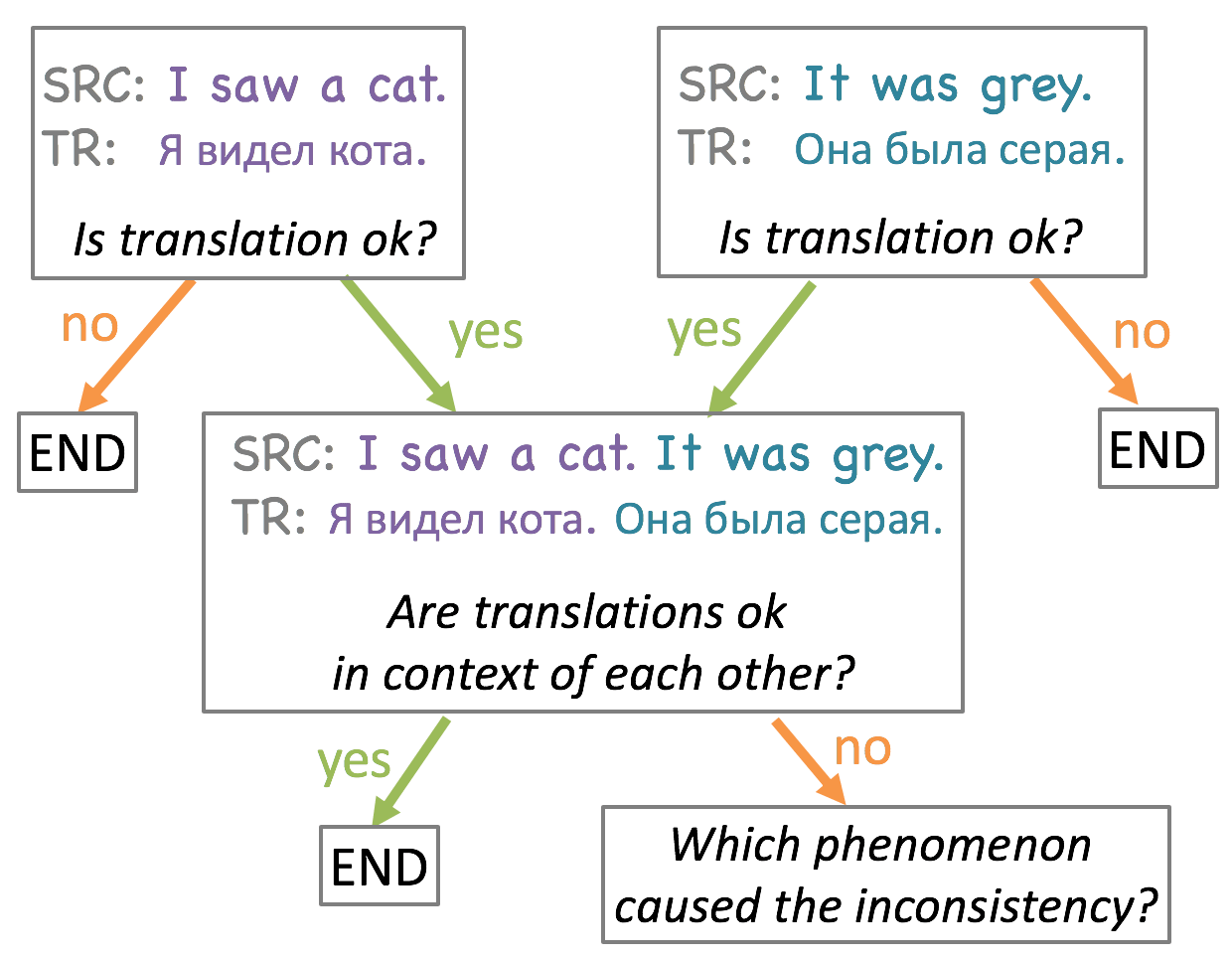
To find the proportion of translation errors which are only recognized as such in context, and to understand which phenomena cause context-agnostic translations not to work together, we conduct a human study as schematically shown in the picture. For simplicity, we start with pairs of consecutive sentences. We use OpenSubtitles dataset for English-Russian language pair and produce context-agnostic translations with the Transformer model trained on this dataset.
 From the table, we see that our annotators labeled
82% of sentence pairs as good
translations. In 11% of cases, at least one translation was considered bad at the sentence level, and in another 7%,
the sentences were considered individually good, but bad in context of each other. This means that in our setting,
a substantial proportion of translation errors are only recognized as such in context.
From the table, we see that our annotators labeled
82% of sentence pairs as good
translations. In 11% of cases, at least one translation was considered bad at the sentence level, and in another 7%,
the sentences were considered individually good, but bad in context of each other. This means that in our setting,
a substantial proportion of translation errors are only recognized as such in context.
Types of Phenomena
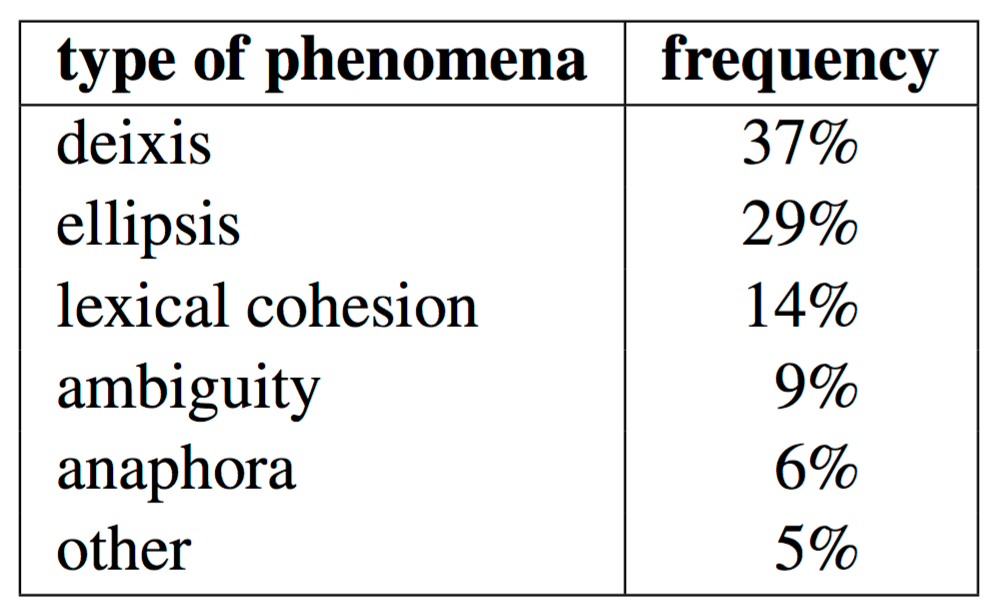 From the results of the human annotation, we take all instances of consecutive sentences with good
translations which become incorrect when placed in the context of each other. For each, we identify the
language phenomenon which caused a discrepancy. The results are provided in the table.
From the results of the human annotation, we take all instances of consecutive sentences with good
translations which become incorrect when placed in the context of each other. For each, we identify the
language phenomenon which caused a discrepancy. The results are provided in the table.
Below we discuss these types of phenomena and problems in translation they cause in more detail. We concentrate only on the three most frequent phenomena.
Deixis
Deictic words or phrases are referential expressions whose denotation depends on context. For example, if you hear "I'm here telling you this", you most probably won't understand who is "I", where is "here", who is "you" and what is "this" unless you are a part of the situation.
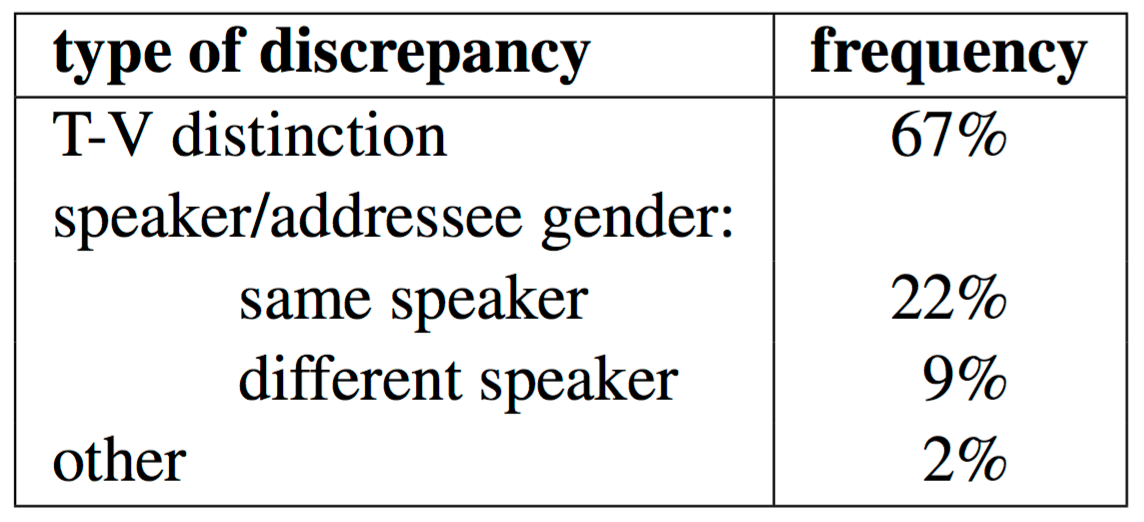
Violation of T-V form consistency.
In color: red - T-from, blue - V-form

Violation of T-V form consistency
(also marked on verbs).
In color: red - T-from, blue - V-form

Violation of gender speaker consistency
(marked on verbs).
In color: red - feminine, blue - masculine

Violation of gender addressee consistency
(marked on adjective and verb).
In color: red - feminine, blue - masculine

Violation of gender speaker/addressee consistency
when the speaker has changed
(marked on verbs).
In color: red - masculine, blue - feminine
 However, when pronouns refer to the same person, the pronouns, as well as verbs that agree with them, should be
translated using the same form.
However, when pronouns refer to the same person, the pronouns, as well as verbs that agree with them, should be
translated using the same form. The statistics of inconsistency types caused by deixis are provided in the table.
Ellipsis
Do you know what ellipsis is? If you don't, I'll tell you. This is an example of an elliptical structure in the second sentence: while what is meant is "If you don't know what ellipsis is, ...", we omit the underlined part and say "If you don't know, ...". Formally, ellipsis is the omission from a clause of one or more words that are nevertheless understood in the context of the remaining elements.
Wrong morphological form,
incorrectly marking the noun phrase as a subject.

Wrong morphological form
in clarification question,
inconsistent with the original one.

Wrong morphological form,
incorrectly marking the verb as a singular masculine.

Incorrect verb meaning:
correct meaning is “see”,
but MT produces хотели (“want”).
 We classified ellipsis examples which lead to errors in sentence-level translations by the type of
error they cause.
It can be seen that the most frequent problems related to ellipsis
that we find in our annotated corpus are wrong morphological forms. This is followed by wrongly predicted
verbs in case of verb phrase ellipsis in English, which does not exist in Russian, thus requiring the
prediction of the verb in the Russian translation.
We classified ellipsis examples which lead to errors in sentence-level translations by the type of
error they cause.
It can be seen that the most frequent problems related to ellipsis
that we find in our annotated corpus are wrong morphological forms. This is followed by wrongly predicted
verbs in case of verb phrase ellipsis in English, which does not exist in Russian, thus requiring the
prediction of the verb in the Russian translation.
Lexical Cohesion

Name translation inconsistency.
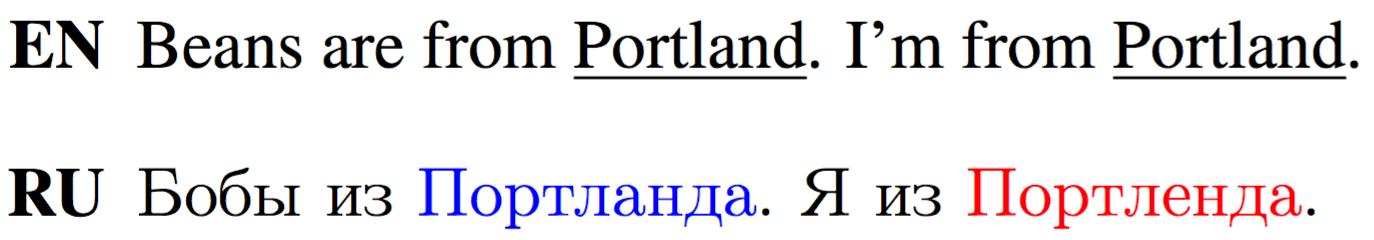
Town translation inconsistency.

Inconsistent translation.
Using either of the highlighted translations
consistently would be good.

Inconsistent translation.
Using either of the highlighted translations
consistently would be good.
Look at the examples.
Test Sets
For the most frequent phenomena from the above analysis, we create test sets for targeted evaluation. Each test set contains contrastive examples. It is specifically designed to test the ability of a system to adapt to contextual information and handle the phenomenon under consideration. Each test instance consists of a true example (sequence of sentences and their reference translation from the data) and several contrastive translations which differ from the true one only in the considered aspect. The system is asked to score each candidate example, and we compute the system accuracy as the proportion of times the true translation is preferred over the contrastive ones.Important note: all contrastive translations we use are correct plausible translations at a sentence level, and only context reveals the errors we introduce.
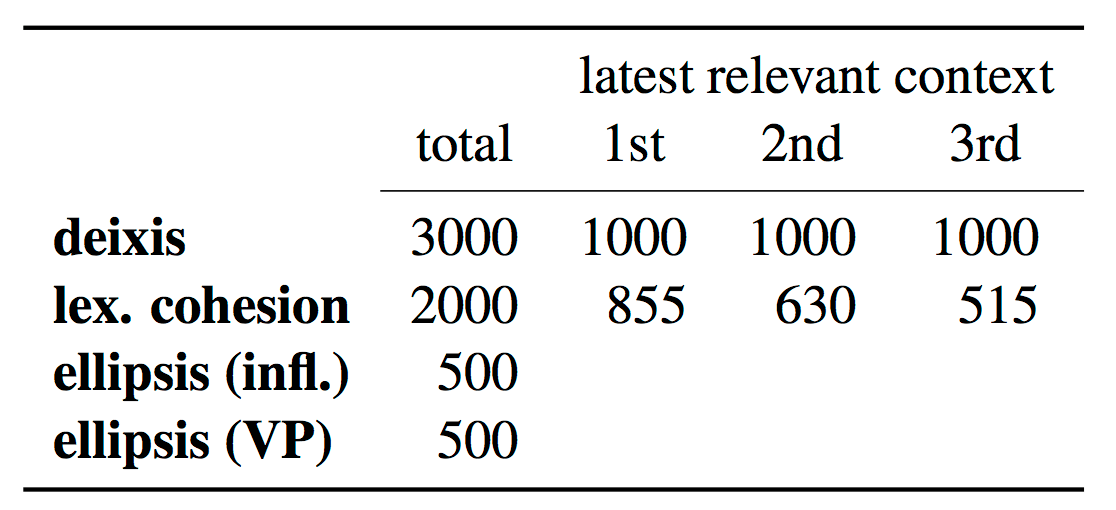 Size of test sets: total number of test instances and with regard to the latest context sentence with politeness
indication or with the named entity under consideration. For ellipsis, we distinguish whether a model has to predict
correct noun phrase inflection, or correct verb sense (VP ellipsis).
Size of test sets: total number of test instances and with regard to the latest context sentence with politeness
indication or with the named entity under consideration. For ellipsis, we distinguish whether a model has to predict
correct noun phrase inflection, or correct verb sense (VP ellipsis).
We discuss each test set and provide some examples below.
Deixis
The test set we construct for deixis tests the ability of a machine translation system to produce translations with consistent level of politeness. We chose this category since the most frequent error category related to deixis in our annotated corpus is the inconsistency of T-V forms when translating second person pronouns.We semi-automatically identify sets of consecutive sentences where both polite and impolite translations are correct. For each, we construct two tasks as shown in the example (red - V-form, blue - T-form; verbs with politeness markers are also colored).

The task is to choose the version of translation with politeness which is consistent with translation of context. Note that by design any context-agnostic model has 50% accuracy on the test set.
Ellipsis
The two most frequent types of ambiguity caused by the presence of an elliptical structure have different nature, hence we construct individual test sets for each of them.Ellipsis (infl.)
Ambiguity of the first type comes from the inability to predict the correct morphological form of some words. We manually gather examples with such structures in a source sentence and change the morphological inflection of the relevant target phrase to create contrastive translations. Specifically, we focus on noun phrases where the verb is elided, and the ambiguity lies in how the noun phrase is inflected.Look at the example of the task: all translations of the current sentence mean "My sister", but have different morphological inflection.

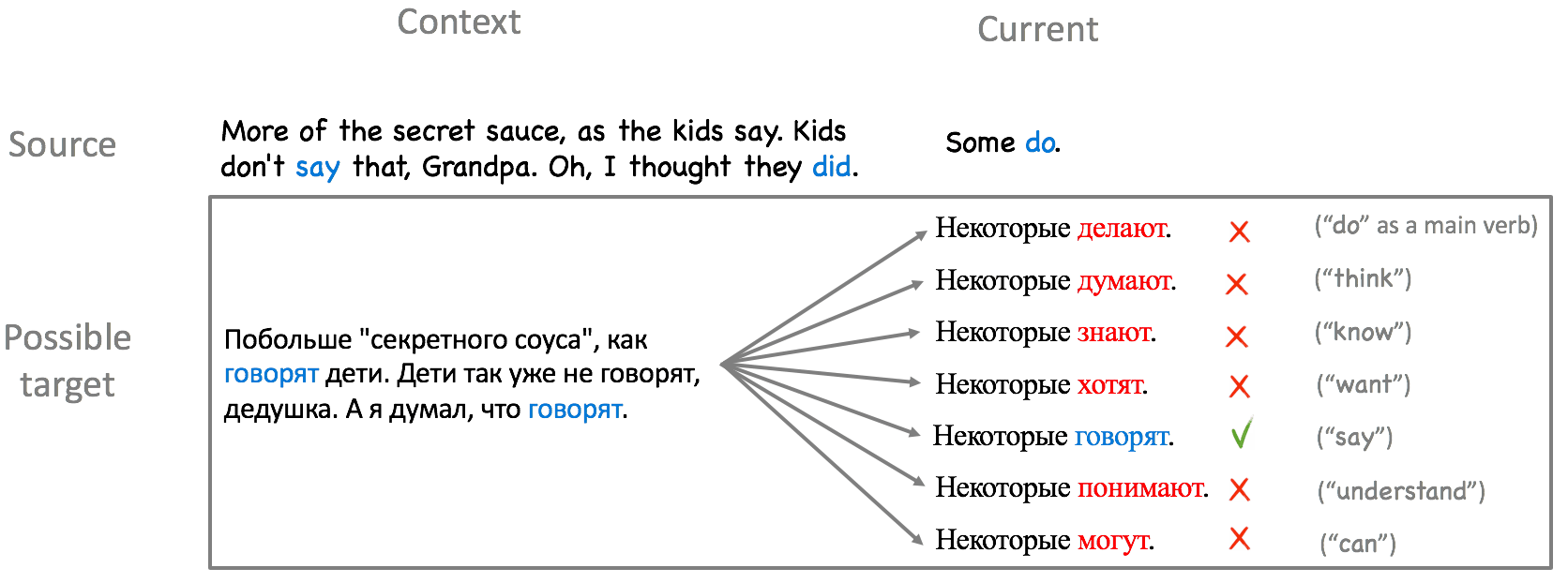
Ellipsis (VP)
The second type we evaluate are verb phrase ellipses. Mostly these are sentences with an auxiliary verb “do” and omitted main verb. We manually gather such examples and replace the translation of the verb, which is only present on the target side, with other verbs with a different meaning, but the same inflection. Verbs which are used to construct such contrastive translations are the top-10 lemmas of translations of the verb “do” which we get from the lexical table of Moses induced from the training data.Look at the example (we show less than 10 lemmas for simplicity). Only one of the provided possible translations of "do" means "say".
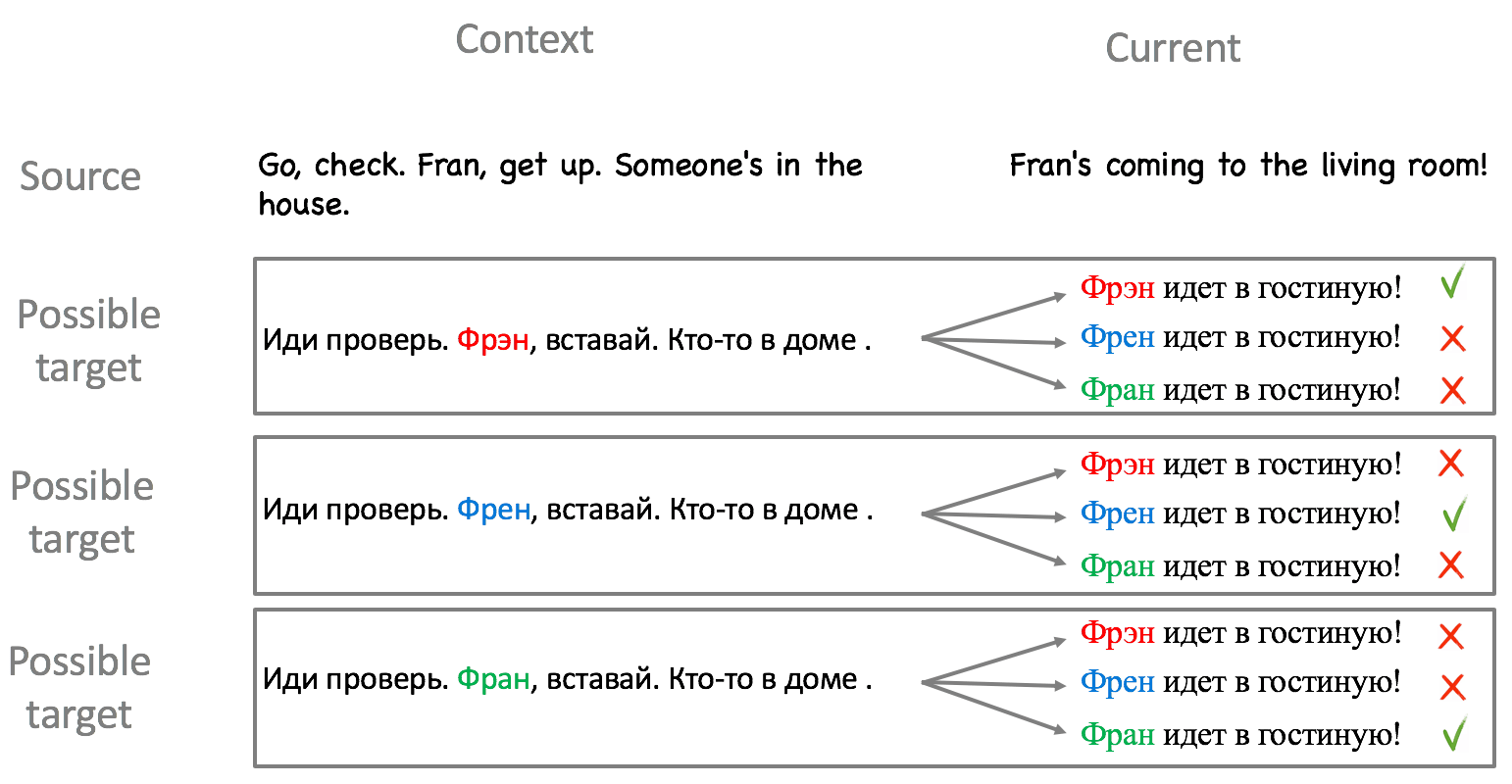
Lexical cohesion
Lexical cohesion can be established for various types of phrases and can involve reiteration or other semantic relations. In the scope of the current work, we focus on the reiteration of entities, since these tend to be non-coincidental, and can be easily detected and transformed. We identify named entities with alternative translations into Russian, find passages where they are translated consistently, and create contrastive test examples by switching the translation of some instances of the named entity.Look at the example. When translating into Russian, three different translations of "Fran" are possible: Фрэн, Френ and Фран. For each of the possible translations of this name in context, the system has to keep the translation of the name in the current sentence consistent with the one in the context.
CADec: Context-Aware Decoder
Setting
TL;DR: A lot of sentence-level data; much less of document-level
Usually when dealing with context-aware NMT it is assumed that all the bilingual data is available at the document level. However, isolated parallel sentences are a lot easier to acquire and hence only a fraction of the parallel data will be at the document level in a practical scenario. In other words, a context-aware model trained only on document-level parallel data is highly unlikely to outperform a context-agnostic model trained on a much larger sentence-level parallel corpus.We argue that it is important to consider an asymmetric setting where the amount of available document-level data is much smaller than that of sentence-level data, and propose an approach specifically targeting this scenario.
Model
We have: a lot of sentence-level data, a small subset of which is at the document level.We want: a strong NMT system which produces consistent at the document level translations.
In our method, the initial translation produced by a baseline context-agnostic model is refined by a context-aware system which is trained on a small document-level subset of parallel data. As the first-pass translation is produced by a strong model, we expect no loss in general performance when training the second part on a smaller dataset.
Look at the illustration of this process.
More formally, the first part of the model is a context-agnostic model (we refer to it as the base model), and the second one is a context-aware decoder (CADec) which refines context-agnostic translations using context. The base model is trained on sentence-level data and then fixed. It is used only to sample context-agnostic translations and to get vector representations of the source and translated sentences. CADec is trained only on data with context.
At training time, to get a draft translation of the current sentence we either sample a translation from the base model or use a corrupted version of the reference translation with the probability p = 0.5. At test time, draft translation is obtained from the base model using beam search. The purpose of using a corrupted reference instead of just sampling is to teach CADec to rely on the base translation and not to change it much. We'll discuss the importance of this below.
Experiments
In our experiments, we have 6 million training instances from the OpenSubtitles dataset, among which 1.5m have context of three sentences. Base model is trained on 6m instances without context, CADec is trained only on 1.5m instances with context. For the context-aware baseline we also consider a naive concatenation model trained on 6m sentence pairs, including 1.5m having 3 context sentences. (We also have another context-aware baseline in the paper, but we do not provide it here for simplicity.)We evaluate in two different ways: using BLEU for general quality and the proposed contrastive test sets for consistency. When evaluating general quality, for context-aware models we translate all sentences including context, and then evaluate only the current one.
Note that BLEU score is likely not to capture consistency. For example, if multiple translations of a name are possible, forcing consistency is essentially as likely to make all occurrences of the name match the reference translation as making them all different from the reference.
We show that models indistinguishable with BLEU can be very different in terms of consistency.
Results
TL;DR: Substantial gains in consistency with no loss in BLEU
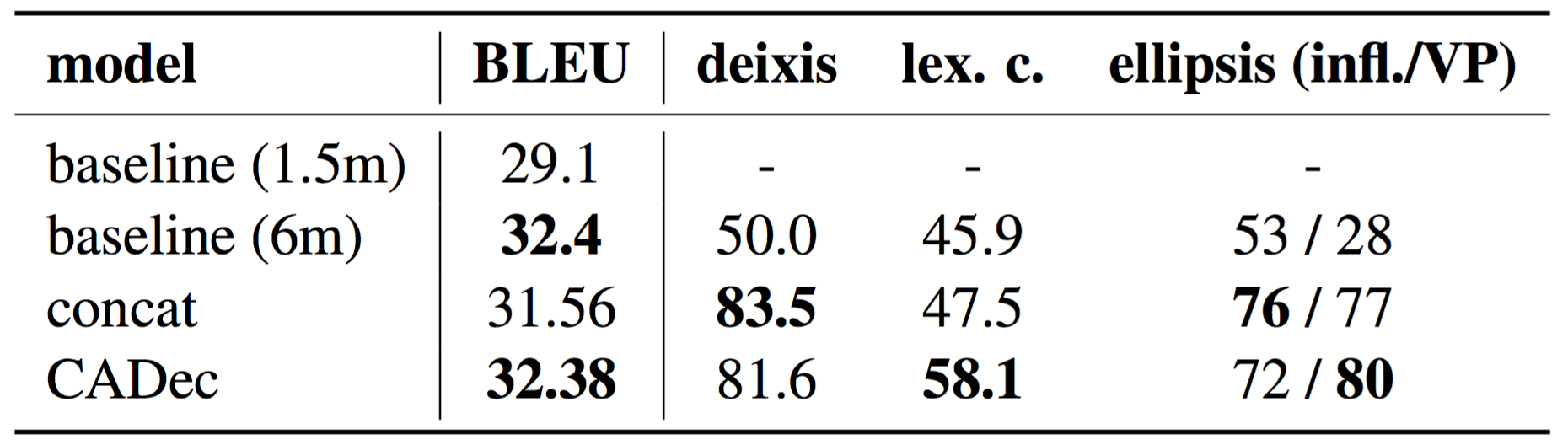 Our model is not worse in BLEU than the baseline despite the second-pass model being trained only on a fraction of the
data. In contrast, the concatenation baseline, trained on a naive mixture of data with and without context, is about
1 BLEU below the context-agnostic baseline and our model when using all 3 context sentences. Note also how the performance is
influenced by the amount of data: the BLEU score for the baseline trained on 1.5m instances is very low.
Our model is not worse in BLEU than the baseline despite the second-pass model being trained only on a fraction of the
data. In contrast, the concatenation baseline, trained on a naive mixture of data with and without context, is about
1 BLEU below the context-agnostic baseline and our model when using all 3 context sentences. Note also how the performance is
influenced by the amount of data: the BLEU score for the baseline trained on 1.5m instances is very low.
Despite CADec is indistinguishable from the baseline in BLEU, it shows substantial gains in consistency: 33.5, 19/52 and 12.2 percentage points for deixis, ellipsis (infl./VP) and lexical cohesion. Concatenation model and CADec perform similarly for deixis and ellipsis, but CADec strongly outperforms the concatenation model in terms of BLEU and lexical cohesion.
Ablation: using corrupted reference
As you remember, at training time CADec uses either a translation sampled from the base model or a corrupted reference translation as the draft translation of the current sentence. Let's say that a corrupted reference is used with probability p. Scores for CADec trained with different values of p are provided in the table.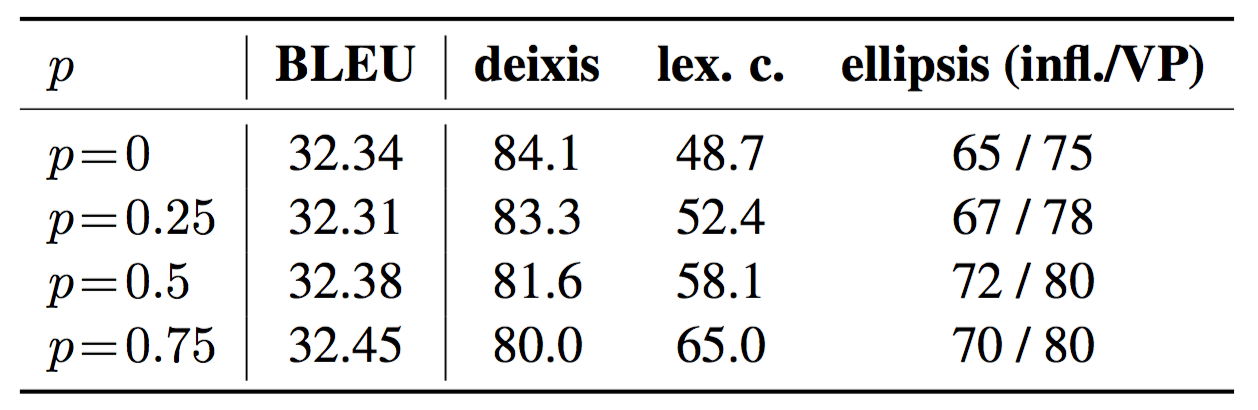
All models have about the same BLEU, not statistically significantly different from the baseline, but they are quite different in terms of incorporating context. The denoising positively influences almost all tasks except for deixis, yielding the largest improvement on lexical cohesion.
This once again indicates the effectiveness of the proposed consistency test sets: without such kind of evaluation, it wouldn't be possible to distinguish models which have the same BLEU score but turn out to be really different in terms of incorporating context.
Context-aware stopping criteria
We randomly choose a fraction of examples from the lexical cohesion set and the deixis test set for validation and leave the rest for final testing. We compute BLEU on the development set as well as scores on lexical cohesion and deixis development sets. We use convergence in both metrics to decide when to stop training.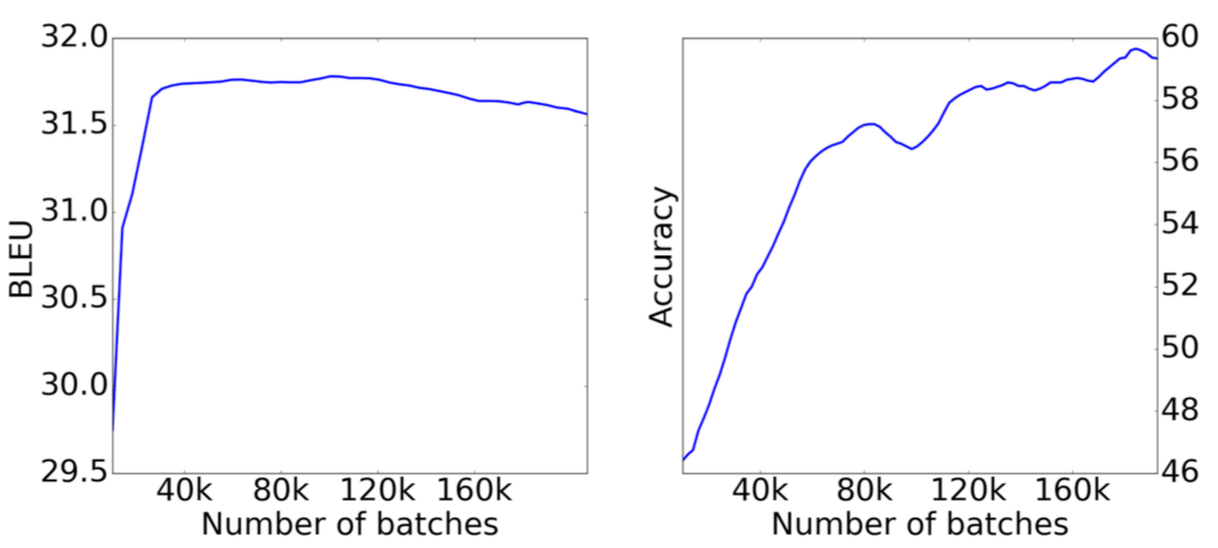
Figure shows that for context-aware models, BLEU is not sufficient as a criterion for stopping: even when a model has converged in terms of BLEU, it continues to improve in terms of consistency. For CADec, BLEU score has stabilized after 40k batches, but the lexical cohesion score continues to grow.
Takeaway message: BLEU is not enough not only for context-aware model selection, but also for early stopping criteria!
Check out: Other contrastive test sets for evaluation of discourse phenomena
For evaluation of context-aware machine translation it is important to use not only BLEU score, but also show how well a model uses contextual information. Here we show other contrastive test sets you can use.EN-FR, Anaphora and coherence/cohesion (200 examples in total)
 Bawden et al., 2018 present hand-crafted
discourse test sets designed to test the models’ ability to exploit previous source and target sentences
(one sentence). There are two test sets in the suite: coreference test set (100 examples) and
coherence/cohesion test set (100 examples). Test sets are designed in a way that any context-agnostic baseline
achieves 50% accuracy.
Look at the example from the coherence/cohesion test set.
Bawden et al., 2018 present hand-crafted
discourse test sets designed to test the models’ ability to exploit previous source and target sentences
(one sentence). There are two test sets in the suite: coreference test set (100 examples) and
coherence/cohesion test set (100 examples). Test sets are designed in a way that any context-agnostic baseline
achieves 50% accuracy.
Look at the example from the coherence/cohesion test set.
EN-DE, Anaphora (12000 examples in total)
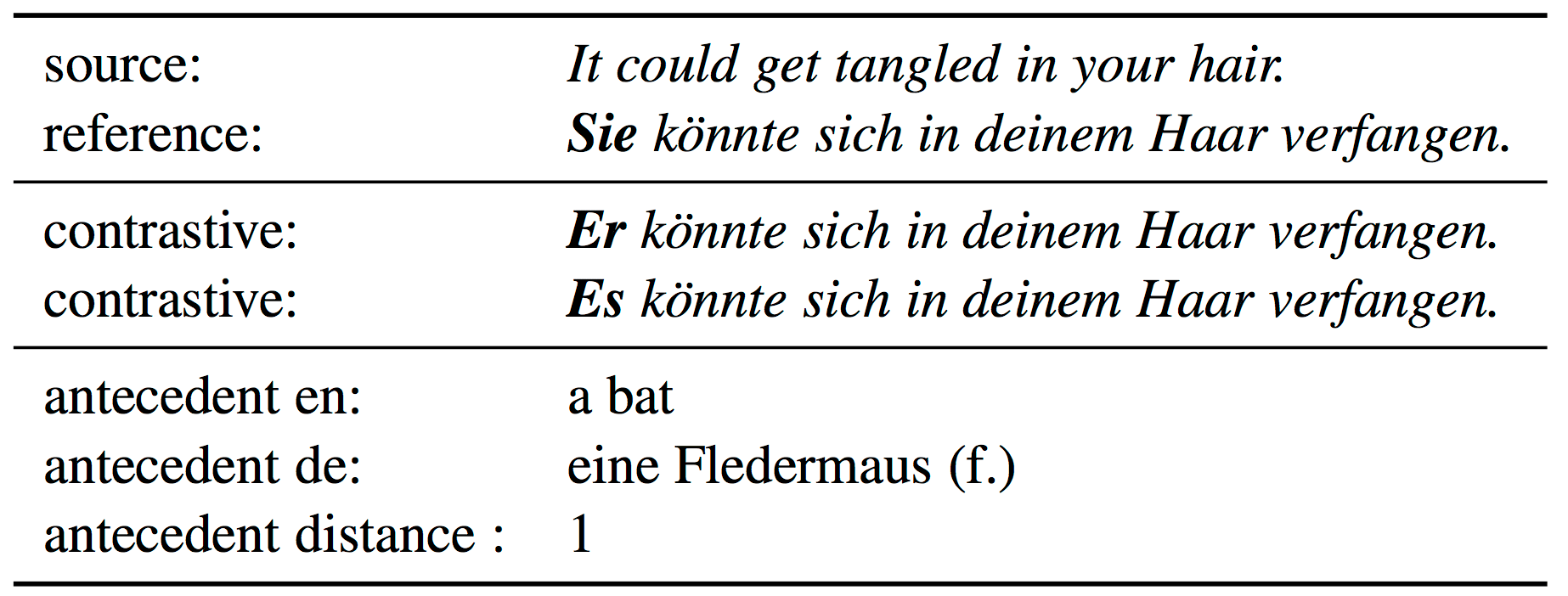 Müller et al., 2018 present a large-scale
test suite of contrastive translations focused specifically on the translation of pronouns.
The test set is used to evaluate the accuracy with which NMT models translate the English
pronoun it to its German counterparts es,
sie and er. One beneficial property of the test set
is a
script for extracting the examples, which can extract any desired number of context sentences.
Müller et al., 2018 present a large-scale
test suite of contrastive translations focused specifically on the translation of pronouns.
The test set is used to evaluate the accuracy with which NMT models translate the English
pronoun it to its German counterparts es,
sie and er. One beneficial property of the test set
is a
script for extracting the examples, which can extract any desired number of context sentences.
Conclusions
We analyze which phenomena cause otherwise good context-agnostic translations to be inconsistent when placed in the context of each other. Our human study on an English–Russian dataset identifies deixis, ellipsis and lexical cohesion as three main sources of inconsistency. We create test sets focusing specifically on the identified phenomena.We consider a novel and realistic set-up where a much larger amount of sentence-level data is available compared to that aligned at the document level and introduce a model suitable for this scenario. We show that our model effectively handles contextual phenomena without sacrificing general quality as measured with BLEU despite using only a small amount of document-level data, while a naive approach to combining sentence-level and document-level data leads to a drop in performance. We show that the proposed test sets allow us to distinguish models (even though identical in BLEU) in terms of their consistency. To build context-aware machine translation systems, such targeted test sets should prove useful, for validation, early stopping and for model selection.
Want to know more?
Share: Tweet