The Story of Heads
 This is a post for the ACL 2019 paper
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned.
This is a post for the ACL 2019 paper
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned.
From this post, you will learn:
- how we evaluate the importance of attention heads in Transformer
- which functions the most important encoder heads perform
- how we prune the vast majority of attention heads in Transformer without seriously affecting quality
- which types of model attention (encoder self-attention, decoder self-attention or decoder-encoder attention) are most sensitive to the number of attention heads and on which layers
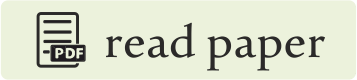

Heads Importance
Previous works analyzing how representations are formed by the Transformer’s multi-head attention mechanism haven't taken into account the varying importance of different heads. Also, this obscures the roles played by individual heads which, as we will show later, influence the generated translations to differing extents.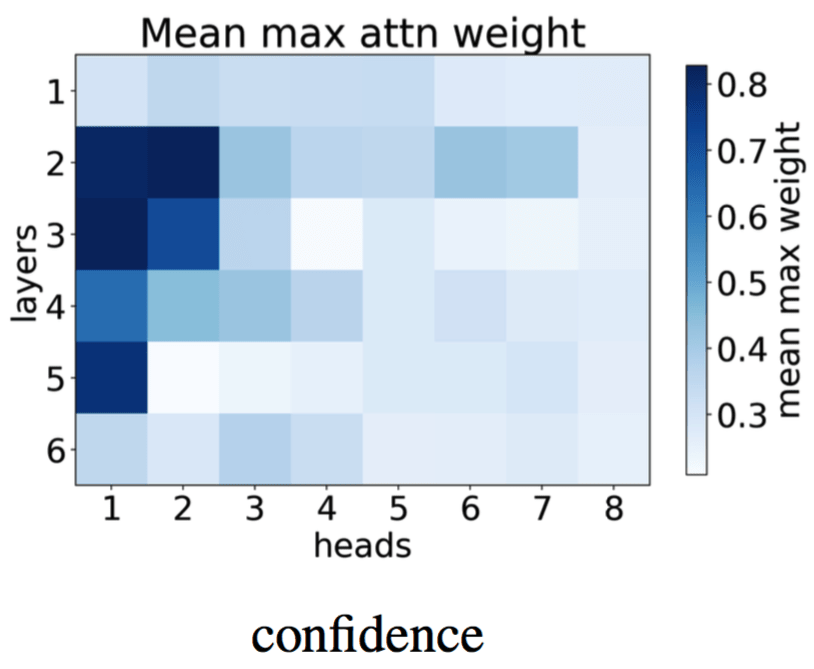 One naive heuristic to detect important heads might be using a head confidence. A confident head is one that usually
assigns a high proportion of its attention to a single token.
We define the “confidence” of a head as the average
of its maximum attention weight excluding the end of sentence
symbol, where average is taken over tokens in a set of sentences used for evaluation (development set).
Intuitively,
we might expect confident heads to be important to the translation task.
One naive heuristic to detect important heads might be using a head confidence. A confident head is one that usually
assigns a high proportion of its attention to a single token.
We define the “confidence” of a head as the average
of its maximum attention weight excluding the end of sentence
symbol, where average is taken over tokens in a set of sentences used for evaluation (development set).
Intuitively,
we might expect confident heads to be important to the translation task.
Figure shows confidence of all heads in the model. We see, that there are a few heads which are extremely confident: on average, they assign more than 80% of their attention mass to a single token.
 While confidence is a really simple heuristic, we want to evaluate a head importance in a more reliable way.
For this, we use
Layerwise Relevance Propagation (LRP).
While confidence is a really simple heuristic, we want to evaluate a head importance in a more reliable way.
For this, we use
Layerwise Relevance Propagation (LRP). LRP was originally designed to compute the contributions of single pixels to predictions of image classifiers. It back-propagates relevance recursively from the output layer to the input layer as shown in the illustration (the illustration is taken from this cool post). To propagate the prediction back, LRP relies on a conservation principle. Intuitively, this means that total contribution of neurons at each layer is constant.
We adapt LRP to the Transformer model to calculate relevance that measures the association degree between two arbitrary neurons in neural networks. The way we use LRP here is different from using attribution methods in computer vision in two important ways:
- we evaluate a neuron/network part importance, not input element (pixel or token),
- we evaluate the importance on average, not for a single prediction.
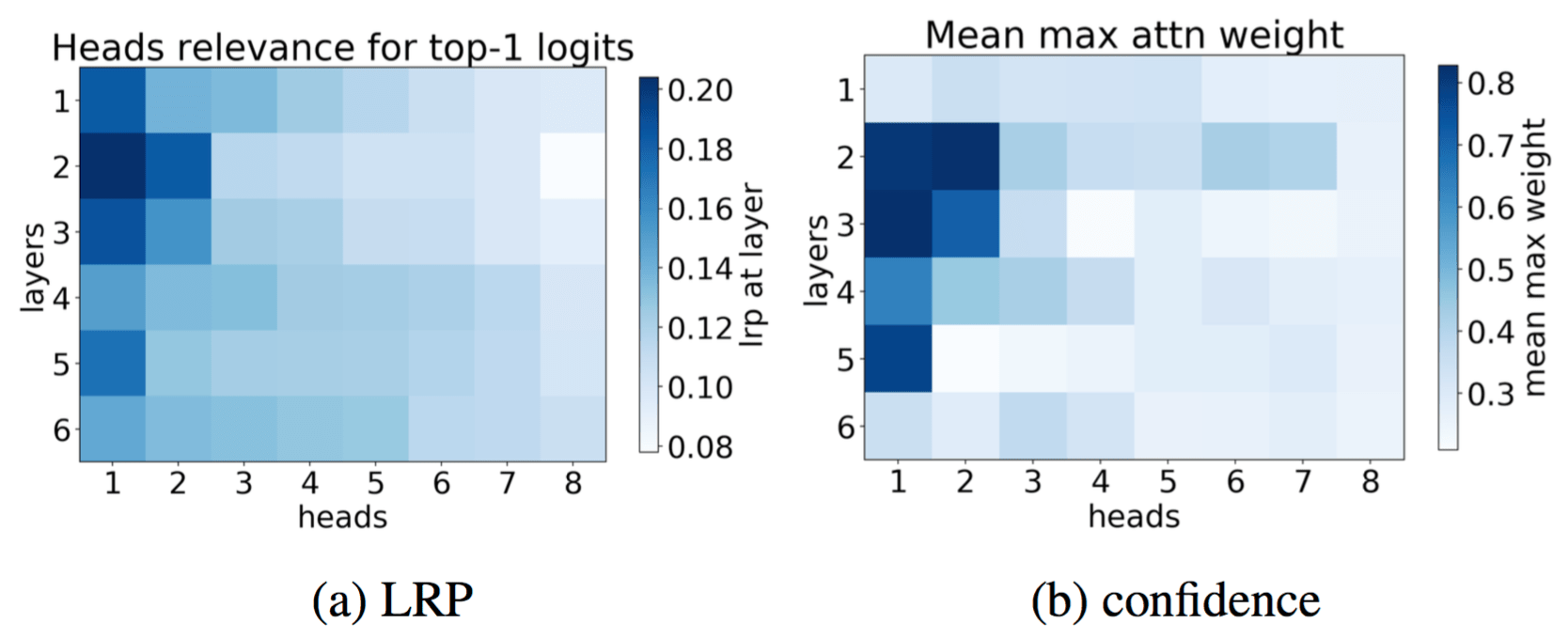 The results of LRP and confidence for the same model are shown in figure (in each layer, heads are sorted by their relevance).
In each layer, LRP ranks a small number of heads as much more
important than the rest.
Also, we see that the relevance of a head as
computed by LRP agrees to a reasonable extent with its confidence. The only clear exception to this pattern
is the head judged by LRP to be the most important in the first layer. It is the most relevant head in the first
layer but its average maximum attention weight is low. We will discuss this head further when characterizing heads' functions.
The results of LRP and confidence for the same model are shown in figure (in each layer, heads are sorted by their relevance).
In each layer, LRP ranks a small number of heads as much more
important than the rest.
Also, we see that the relevance of a head as
computed by LRP agrees to a reasonable extent with its confidence. The only clear exception to this pattern
is the head judged by LRP to be the most important in the first layer. It is the most relevant head in the first
layer but its average maximum attention weight is low. We will discuss this head further when characterizing heads' functions.
Head Functions
We now turn to investigating whether heads play consistent and interpretable roles within the model. We examined some attention matrices paying particular attention to heads ranked highly by LRP and identified three functions which heads might be playing.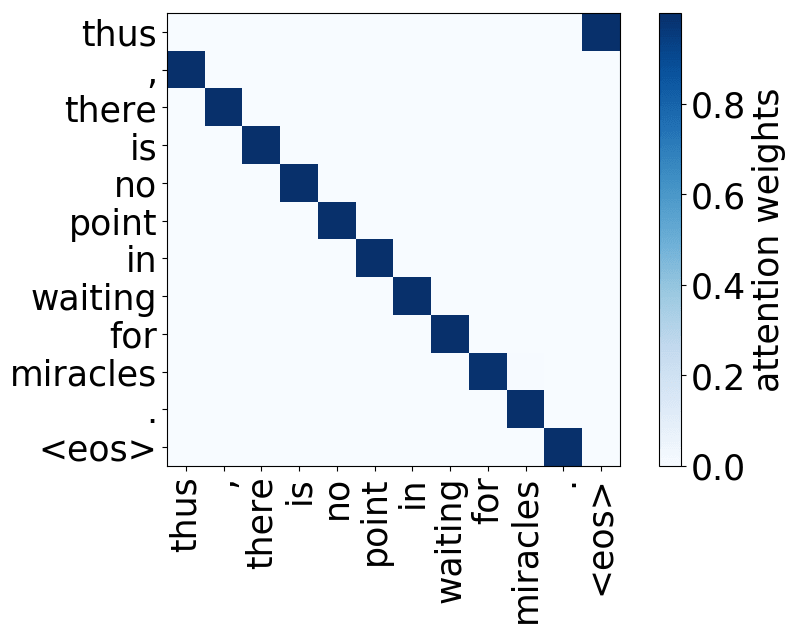
Model trained on WMT EN-DE
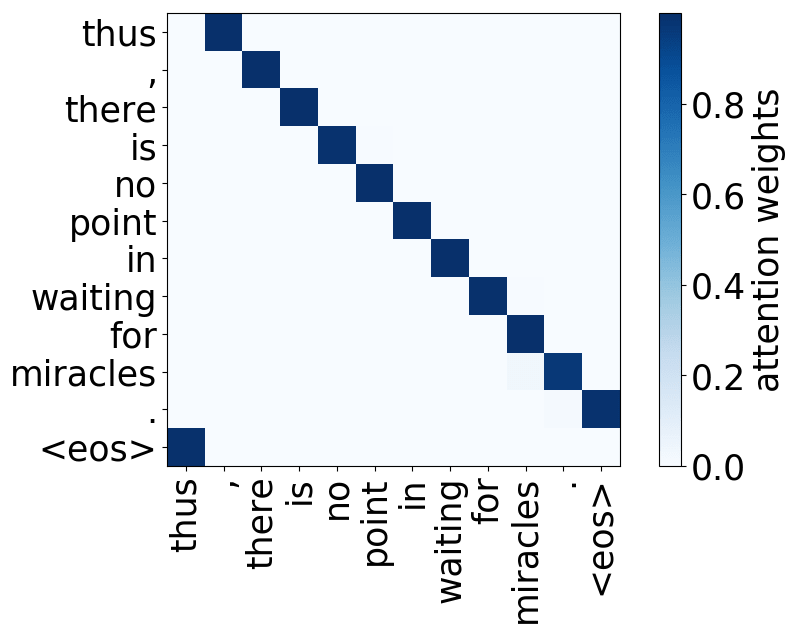
Model trained on WMT EN-DE
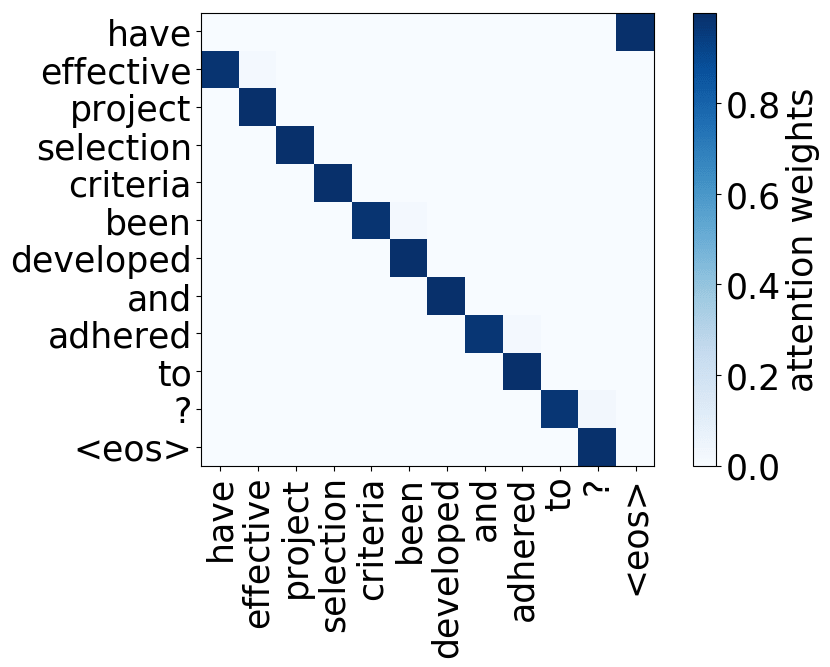
Model trained on WMT EN-FR
Model trained on WMT EN-FR
Model trained on WMT EN-RU
Model trained on WMT EN-RU
Model trained on OpenSubtitles EN-RU
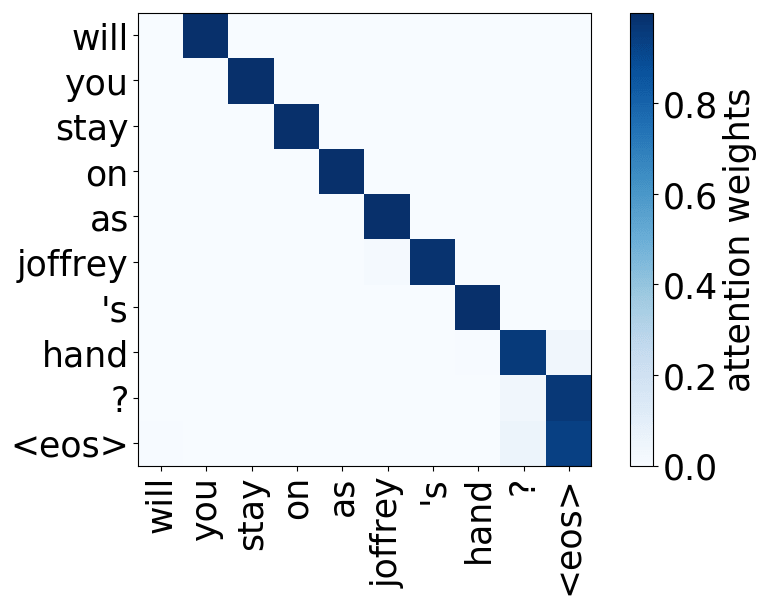
Model trained on OpenSubtitles EN-RU
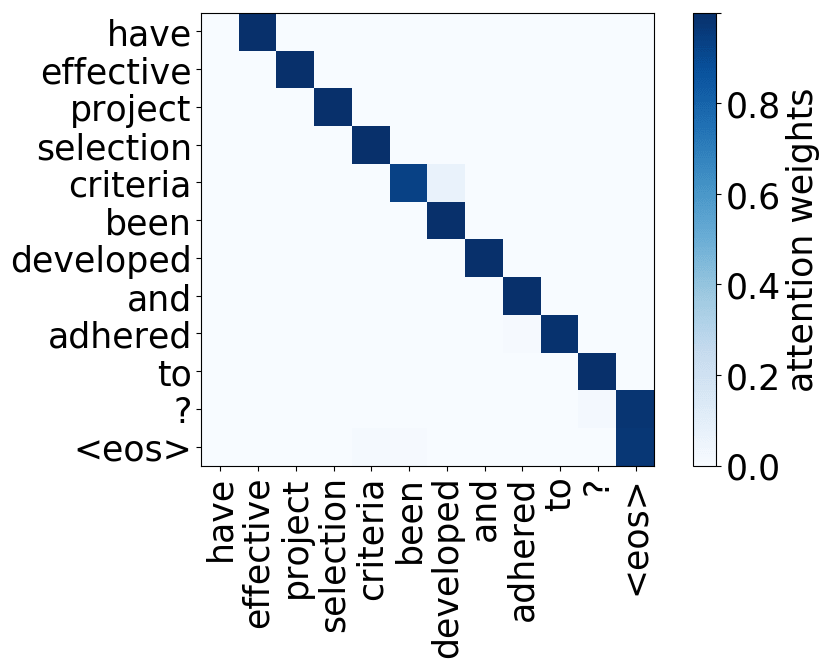
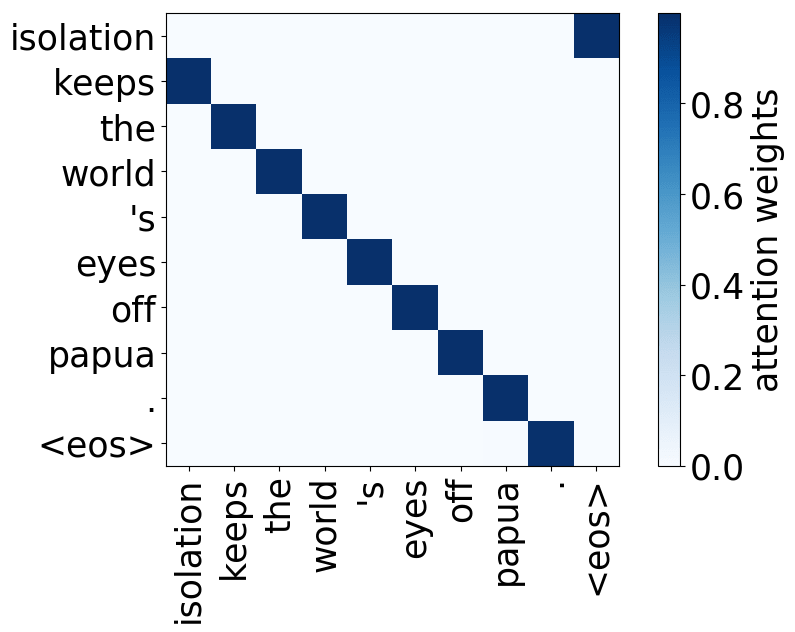
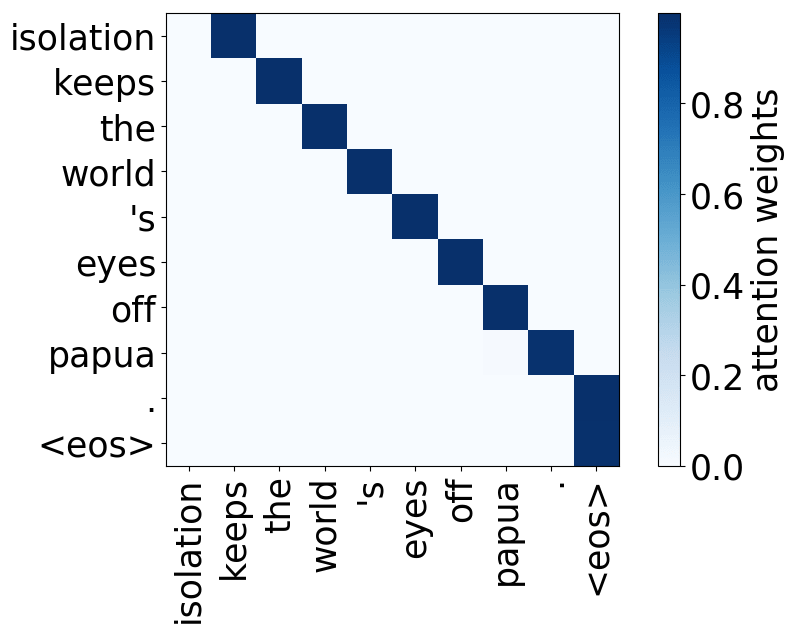
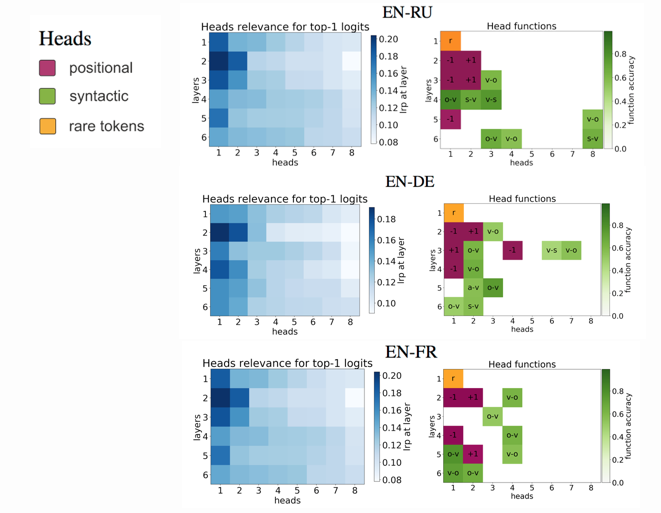
We refer to a head as “positional” if at least 90% of the time its maximum attention weight is assigned to a specific relative position (in practice either -1 or +1, i.e. attention to adjacent tokens).
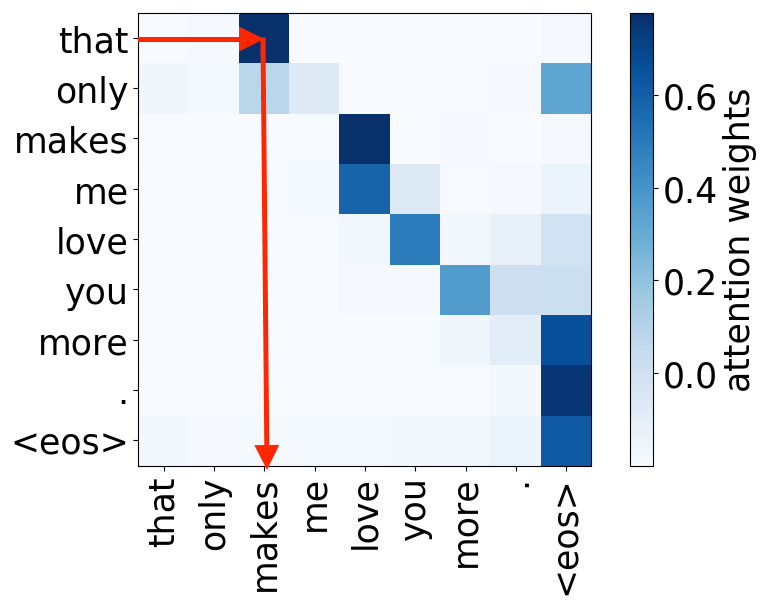
subject-> verb
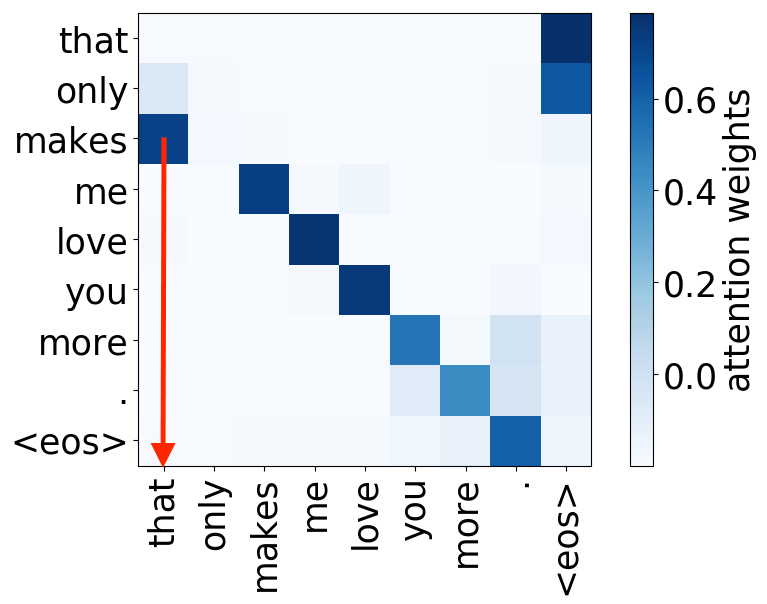
verb -> subject
subject-> verb
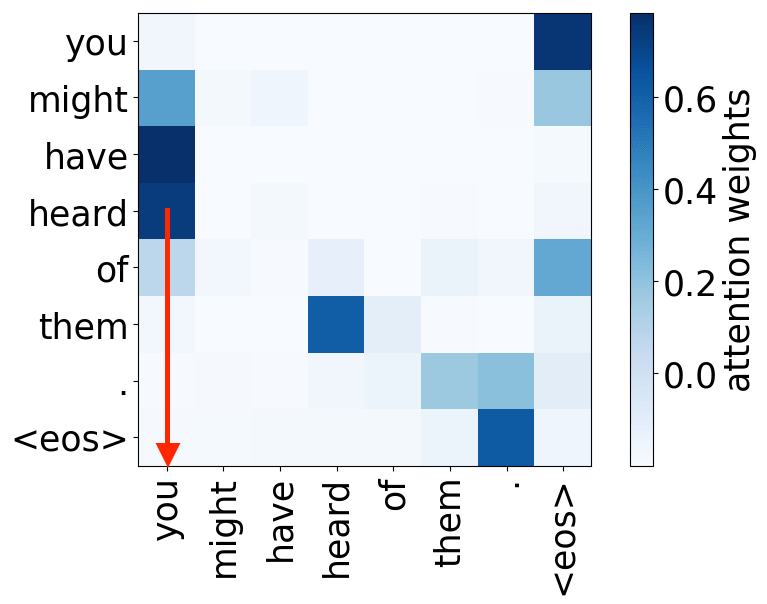
verb -> subject
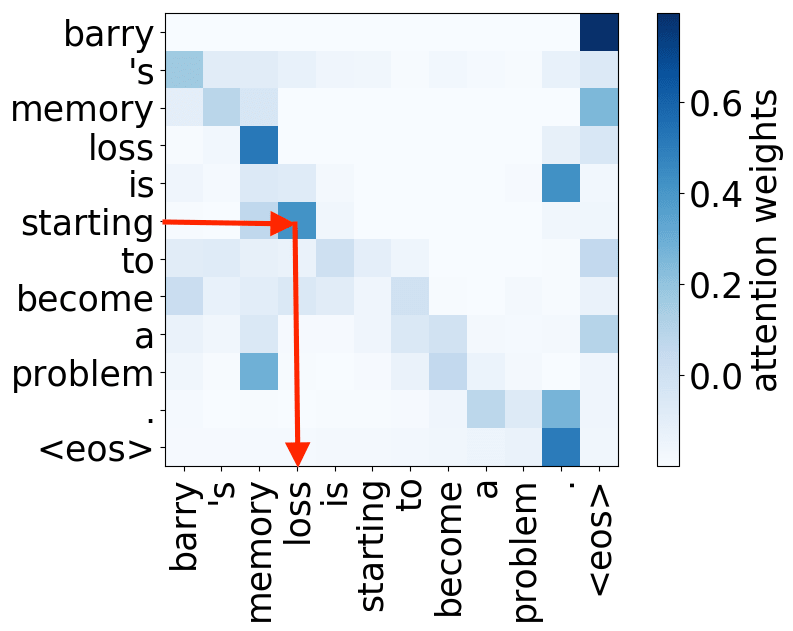
verb -> subject
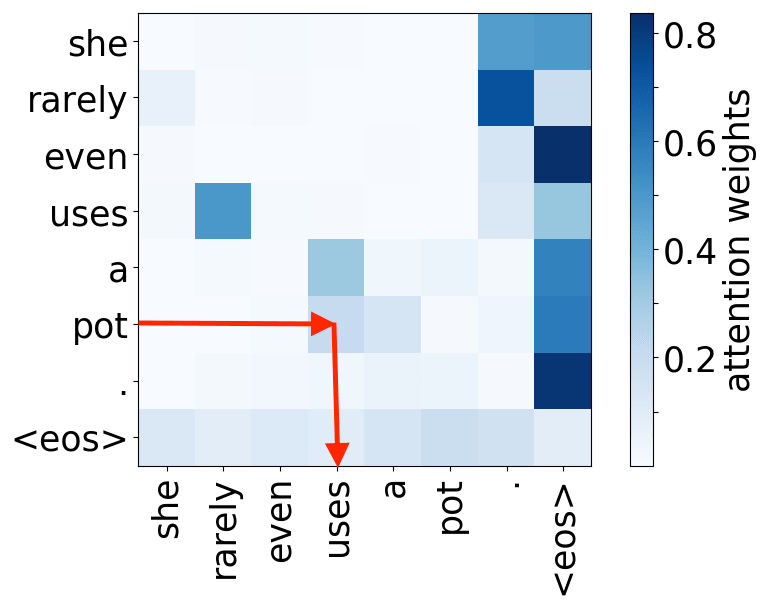
object -> verb
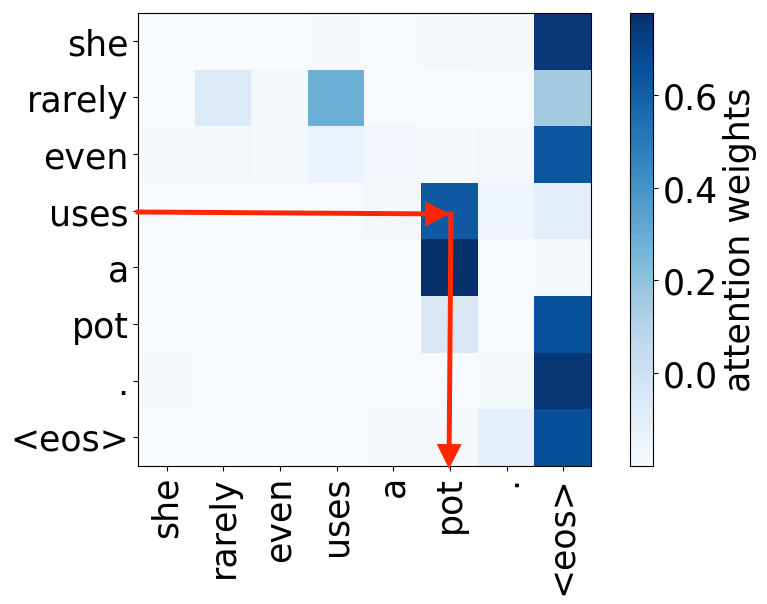
verb -> object
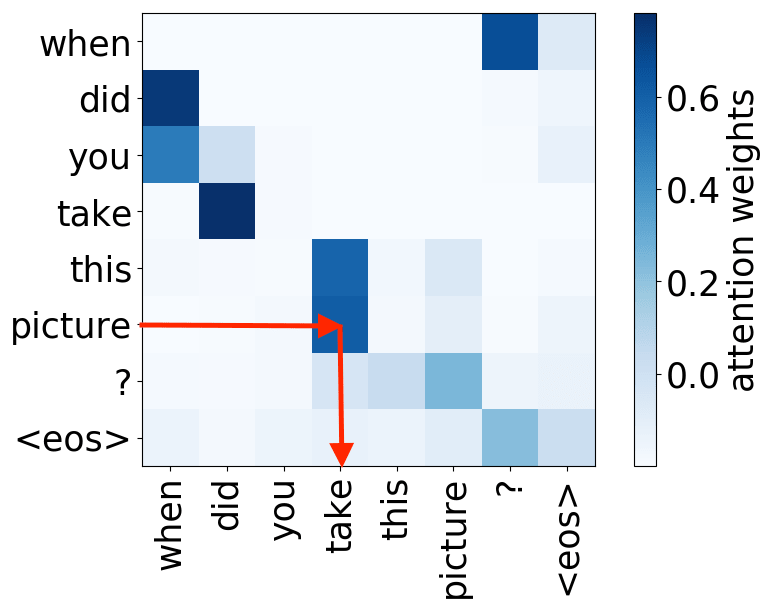
object -> verb
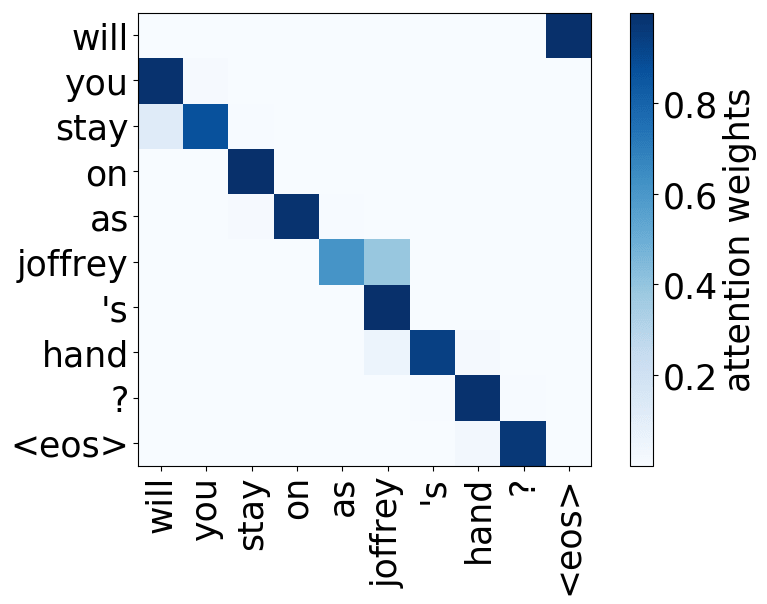
We hypothesize that, when used to perform translation, the Transformer’s encoder may be responsible for disambiguating the syntactic structure of the source sentence. We therefore wish to know whether a head attends to tokens corresponding to any of the major syntactic relations in a sentence. In our analysis, we looked at nominal subject (nsubj), direct object (dobj), adjectival modifier (amod) and adverbial modifier (advmod) relations. We calculate for each head how often it assigns its maximum attention weight (excluding EOS) to a token with which it is in one of the aforementioned dependency relations. We do so by comparing its attention weights to a dependency structure predicted by CoreNLP on a large number of held-out sentences.
For more details, read the paper.
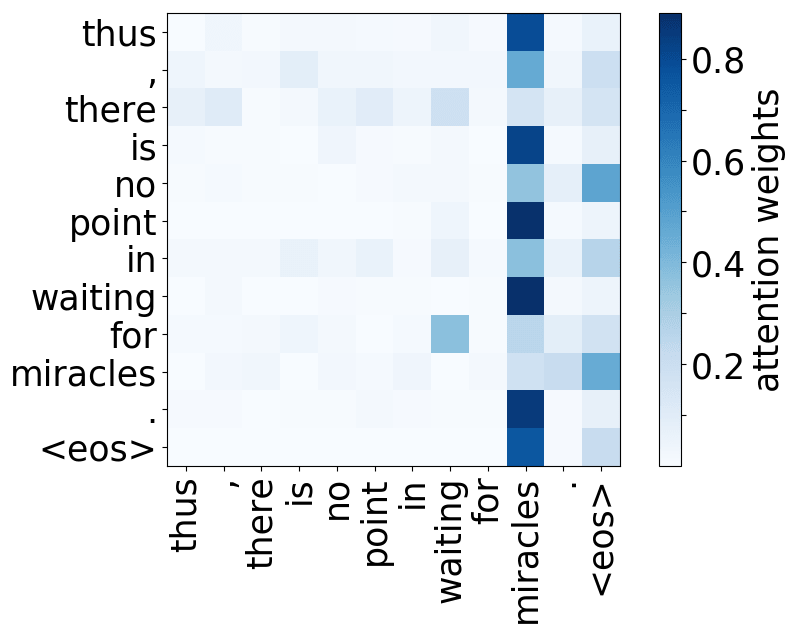
Model trained on WMT EN-DE
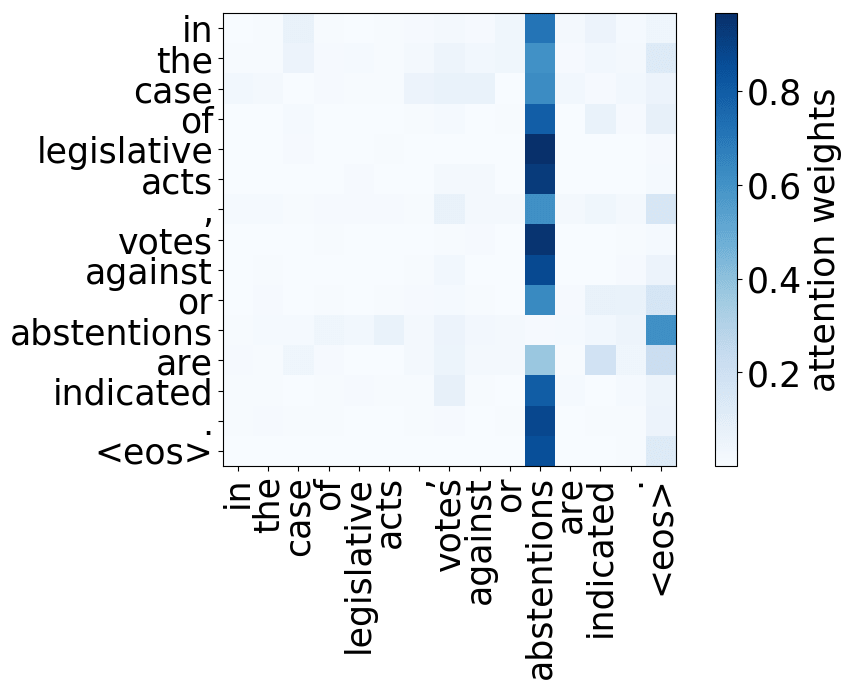
Model trained on WMT EN-DE
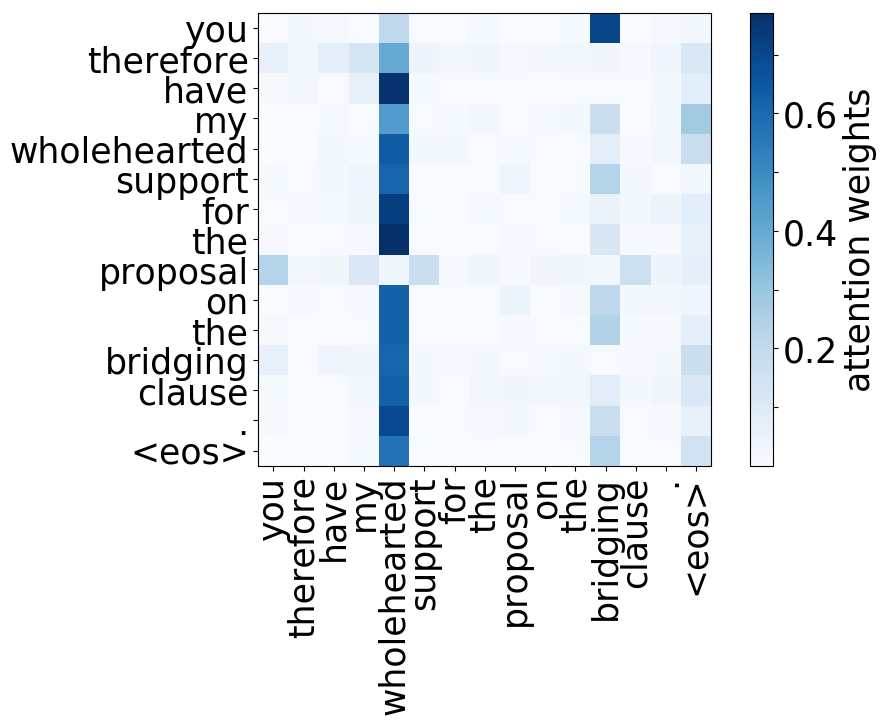
Model trained on WMT EN-DE
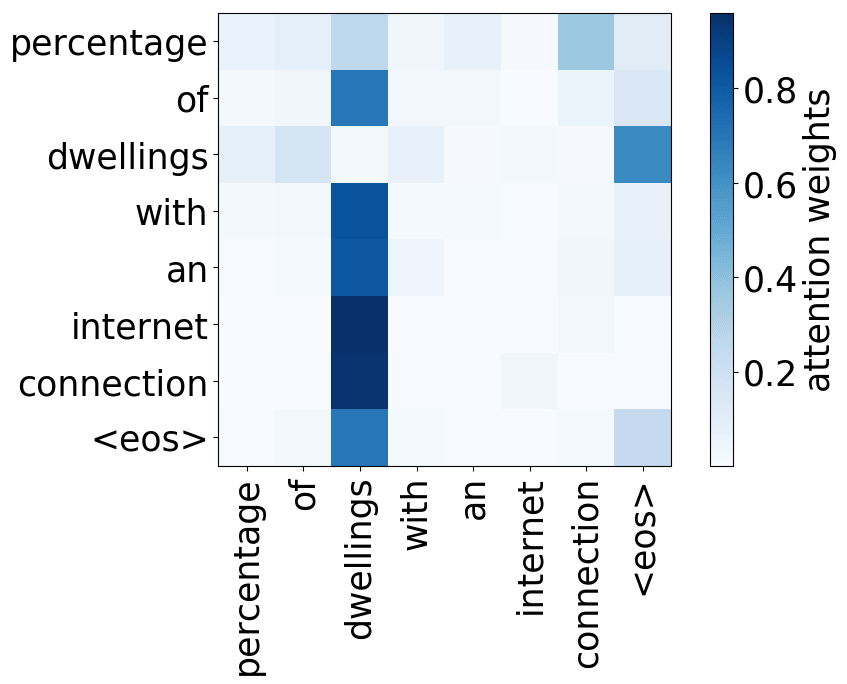
Model trained on WMT EN-FR
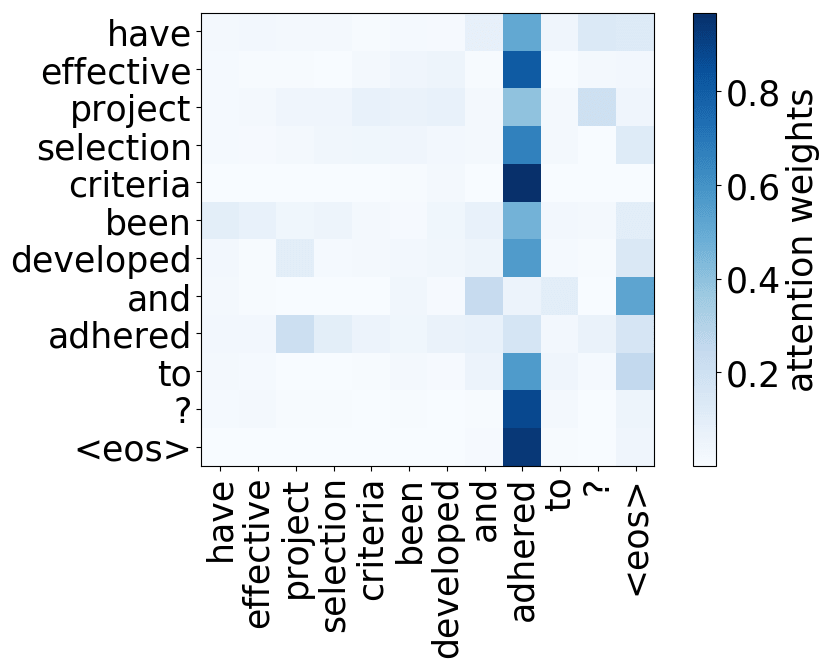
Model trained on WMT EN-FR
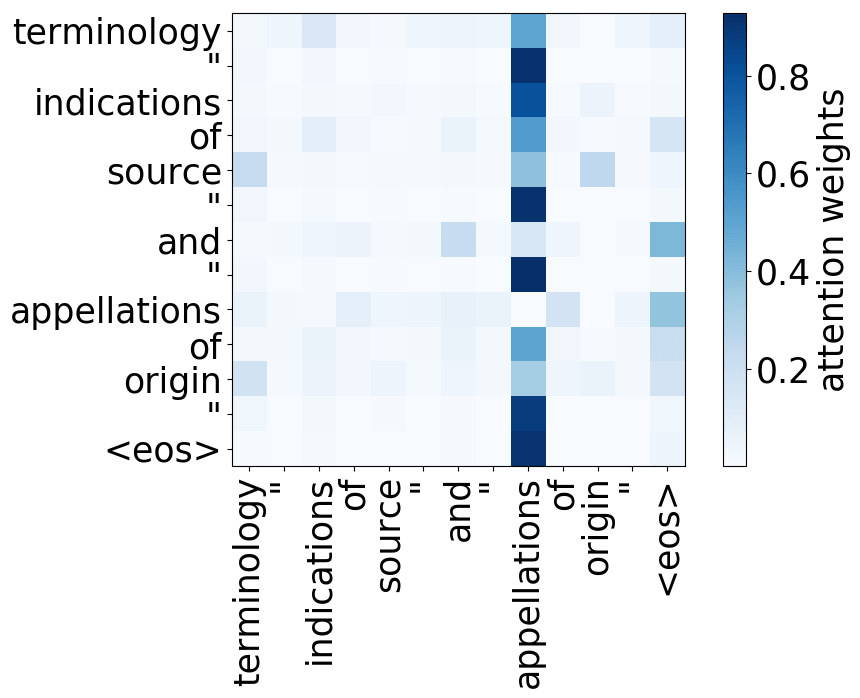
Model trained on WMT EN-FR
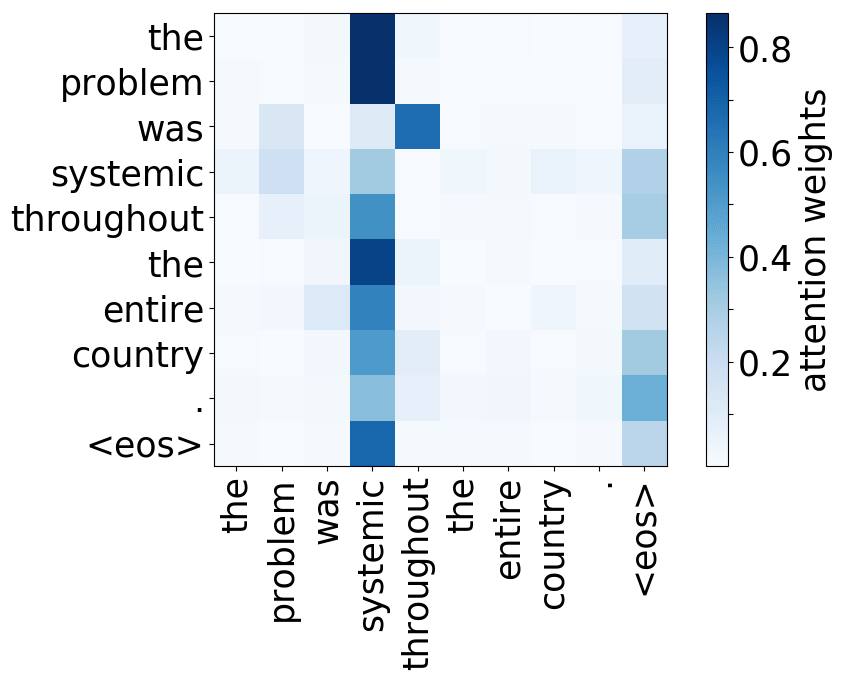
Model trained on WMT EN-RU
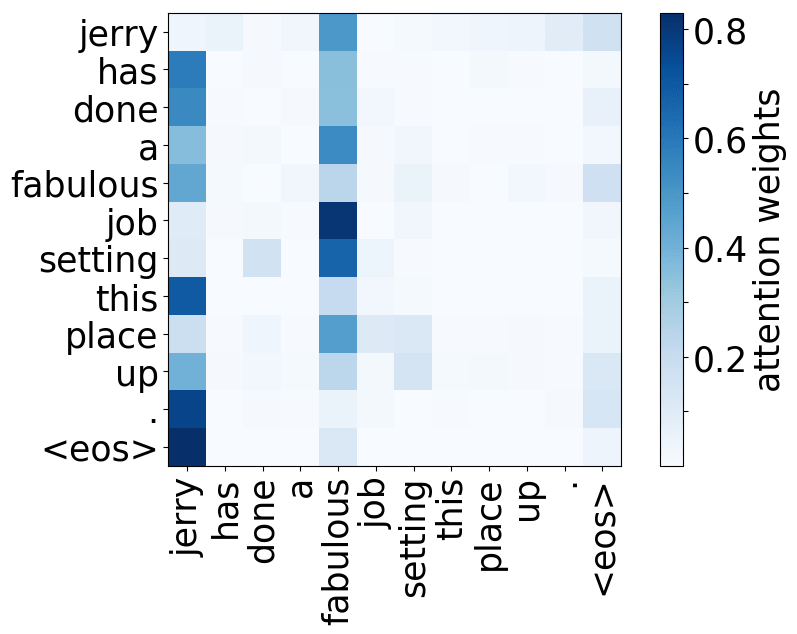
Model trained on WMT EN-RU
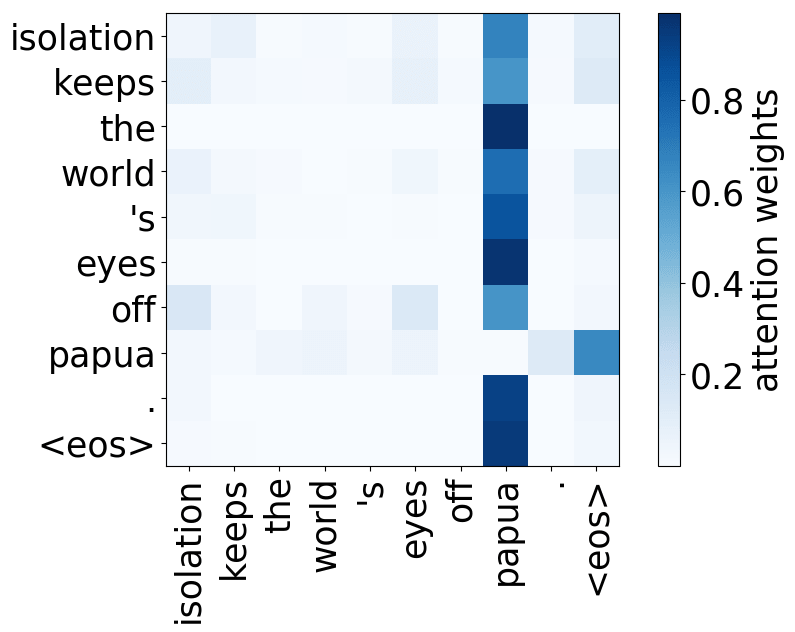
Model trained on WMT EN-RU
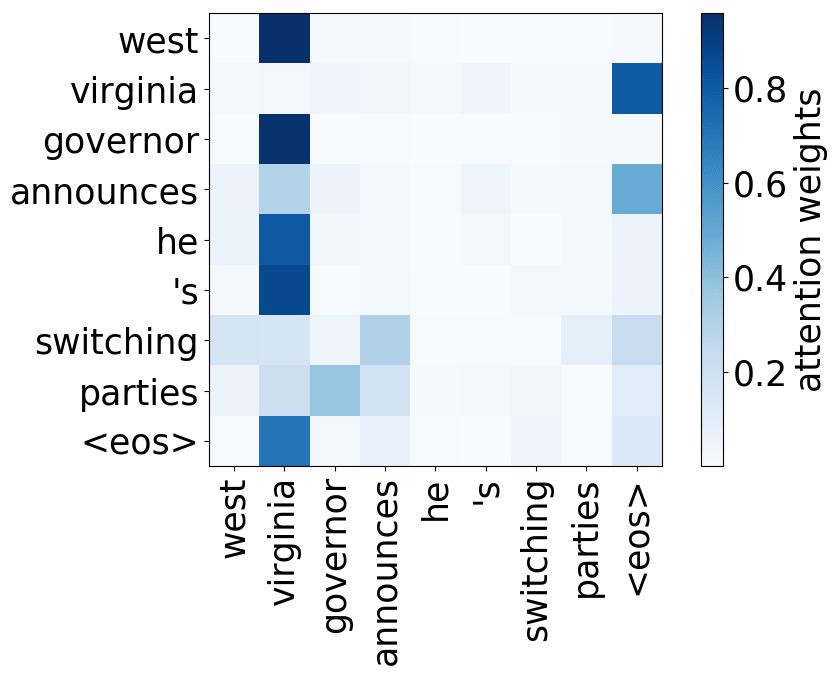
Model trained on WMT EN-RU
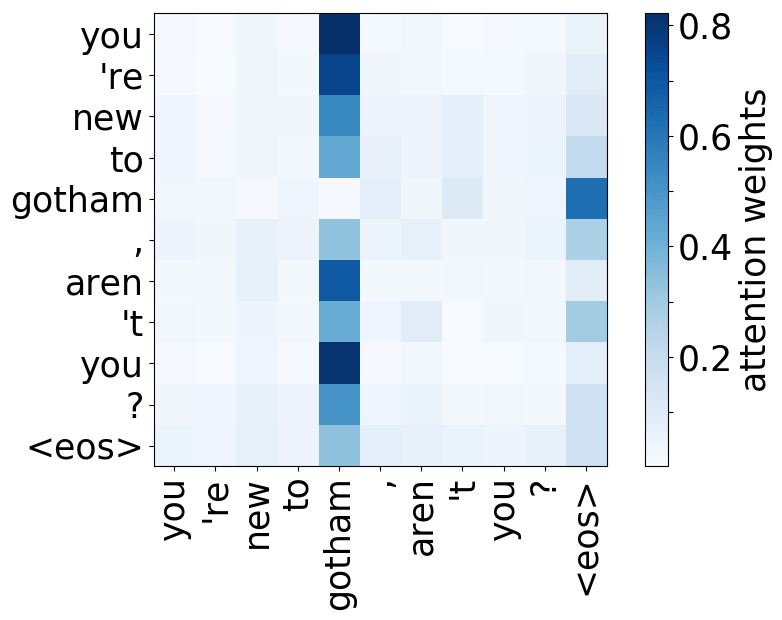
Model trained on OpenSubtitles EN-RU
Model trained on OpenSubtitles EN-RU
Model trained on OpenSubtitles EN-RU
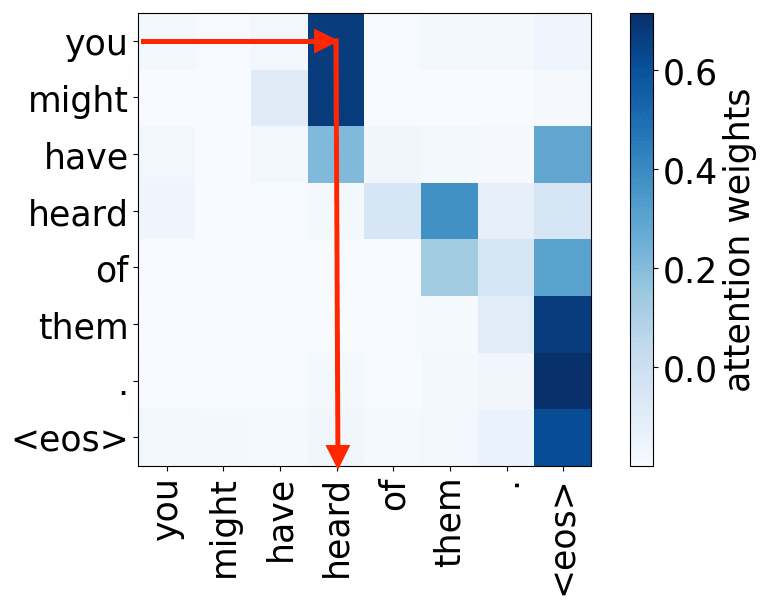
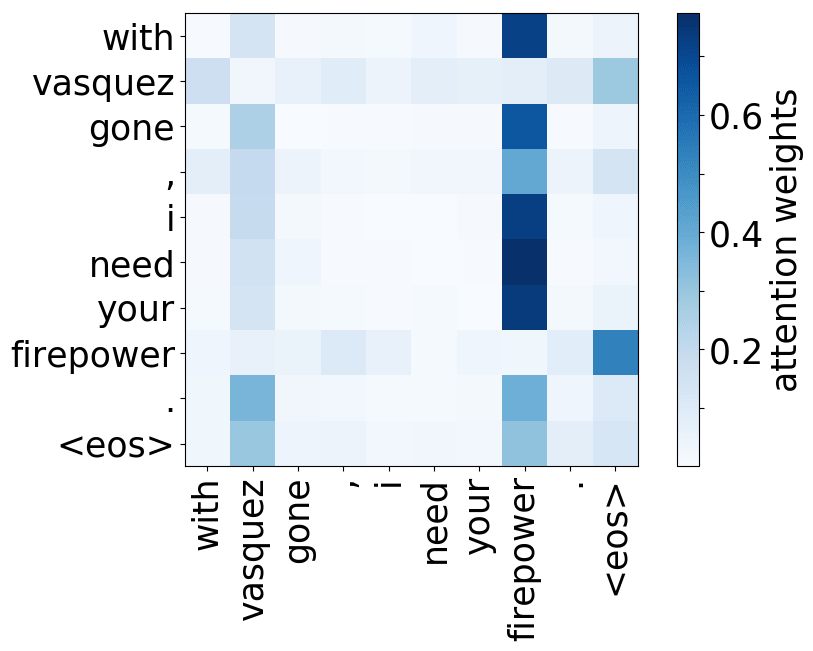
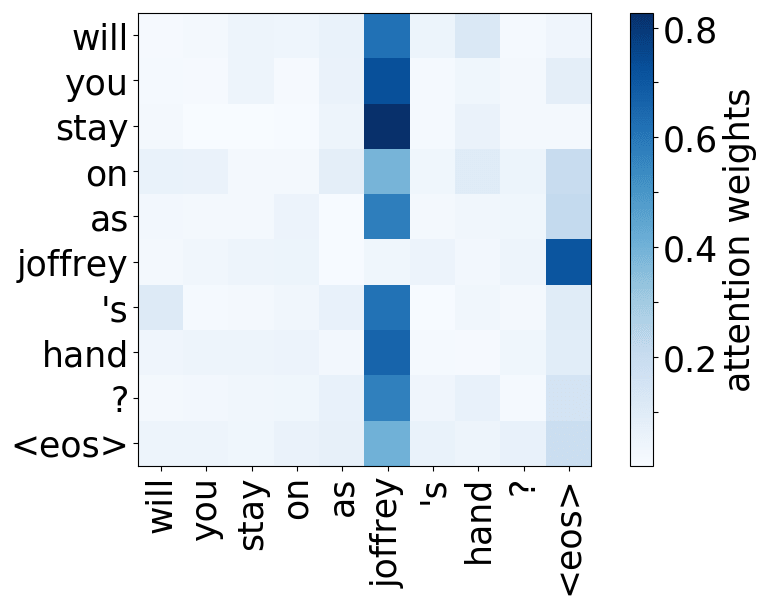
Rare tokens
For all models, we find a head pointing to the least frequent tokens in a sentence. For models trained on OpenSubtitles, among sentences where the least frequent token in a sentence is not in the top-500 most frequent tokens, this head points to the rarest token in 66% of cases, and to one of the two least frequent tokens in 83% of cases. For models trained on WMT, this head points to one of the two least frequent tokens in more than 50% of such cases.
 Let's now look at how these functions correspond to the importancies evaluated earlier.
As can be seen, the positional heads correspond, to a large extent, to the most important heads as ranked by LRP.
In each model, there are several heads tracking syntactic relations, and these heads are also judged to be important by LRP.
In all models, we find that one head in the first layer is
judged to be much more important to the model’s predictions than any other heads in this layer. Interestingly,
this turns out to be the head attending to rare tokens.
Let's now look at how these functions correspond to the importancies evaluated earlier.
As can be seen, the positional heads correspond, to a large extent, to the most important heads as ranked by LRP.
In each model, there are several heads tracking syntactic relations, and these heads are also judged to be important by LRP.
In all models, we find that one head in the first layer is
judged to be much more important to the model’s predictions than any other heads in this layer. Interestingly,
this turns out to be the head attending to rare tokens.
Pruning Attention Heads
We have identified certain functions of the most relevant heads at each layer and showed that to a large extent they are interpretable. What about the remaining heads? Are they useless to translation quality or do they play equally vital but simply less easily defined roles? We introduce a method for pruning attention heads to try to answer these questions.Method
In the standard Transformer, results of different attention heads in a layer are concatenated: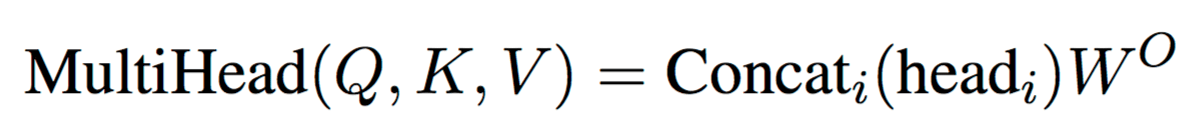 .
.
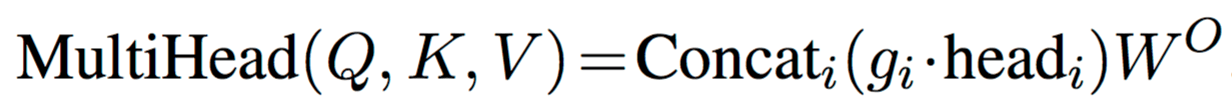 .
.
Unfortunately, the L0 norm is nondifferentiable and so cannot be directly incorporated as a regularization term in the objective function. Instead, we use a stochastic relaxation. Each gate
We use the sum of the probabilities of heads being non-zero (
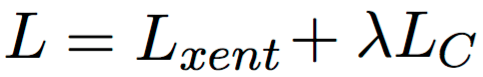 .
.
When applying the regularizer, we start from the converged model trained without the
 The gif shows how the probabilities of encoder heads being completely closed
(
The gif shows how the probabilities of encoder heads being completely closed
(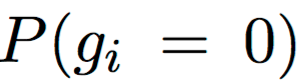 ) change in training
for different values of λ. White color denotes
) change in training
for different values of λ. White color denotes
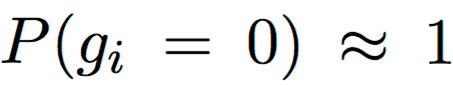 , which means that
a head is completely removed from the model.
(Gif is for the model trained on EN-RU WMT. For other datasets, values of λ can be different.)
, which means that
a head is completely removed from the model.
(Gif is for the model trained on EN-RU WMT. For other datasets, values of λ can be different.)
We observe that the model converges to solutions where gates are either almost completely closed or completely open. This means that at test time we can treat the model as a standard Transformer and use only a subset of heads.
Expected L0 regularization with stochastic gates has also been used in another ACL paper to produce sparse and interpretable classifiers.
BLEU score
Encoder heads
First, let's look how the translation quality is affected by pruning attention heads. The figure below shows BLEU score as a function of number of retained encoder heads (EN-RU). Regularization applied by fine-tuning the trained model.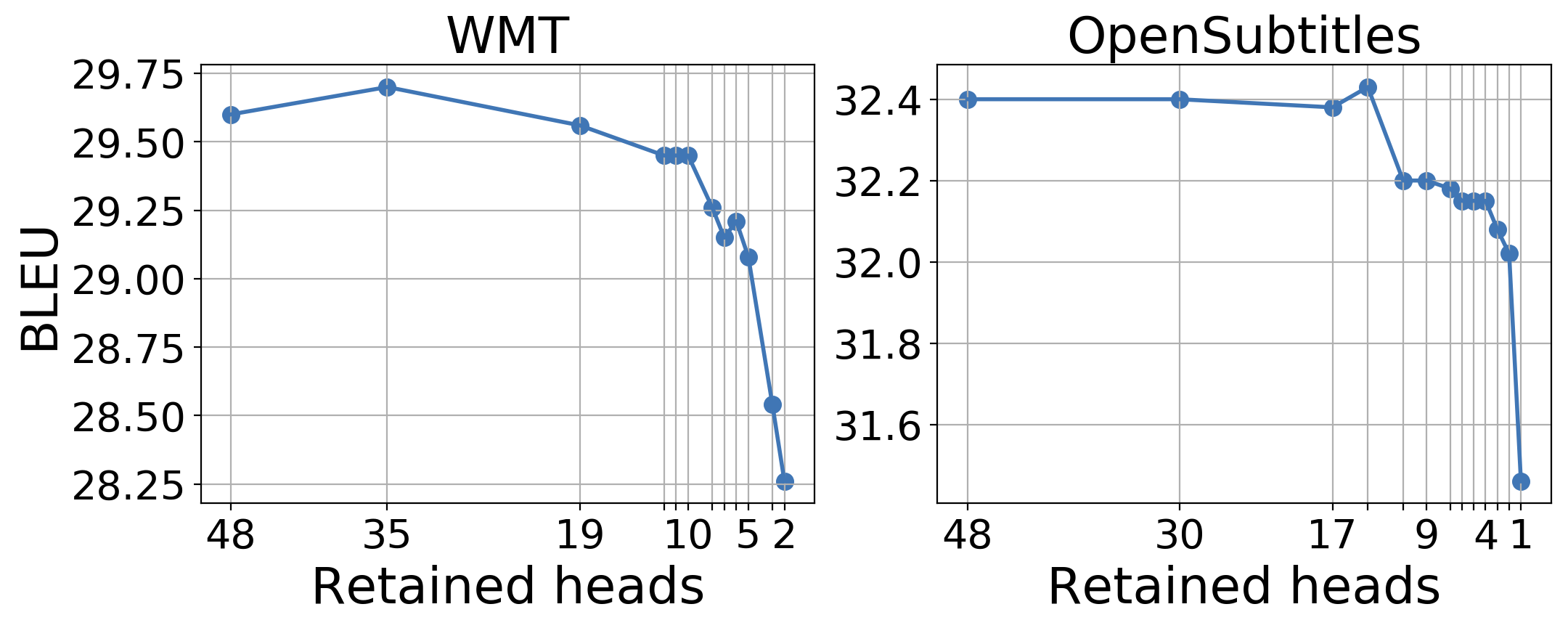
Surprisingly, for OpenSubtitles, we lose only 0.25 BLEU when we prune all but 4 heads out of 48. For the more complex WMT task, 10 heads in the encoder are sufficient to stay within 0.15 BLEU of the full model.
All heads
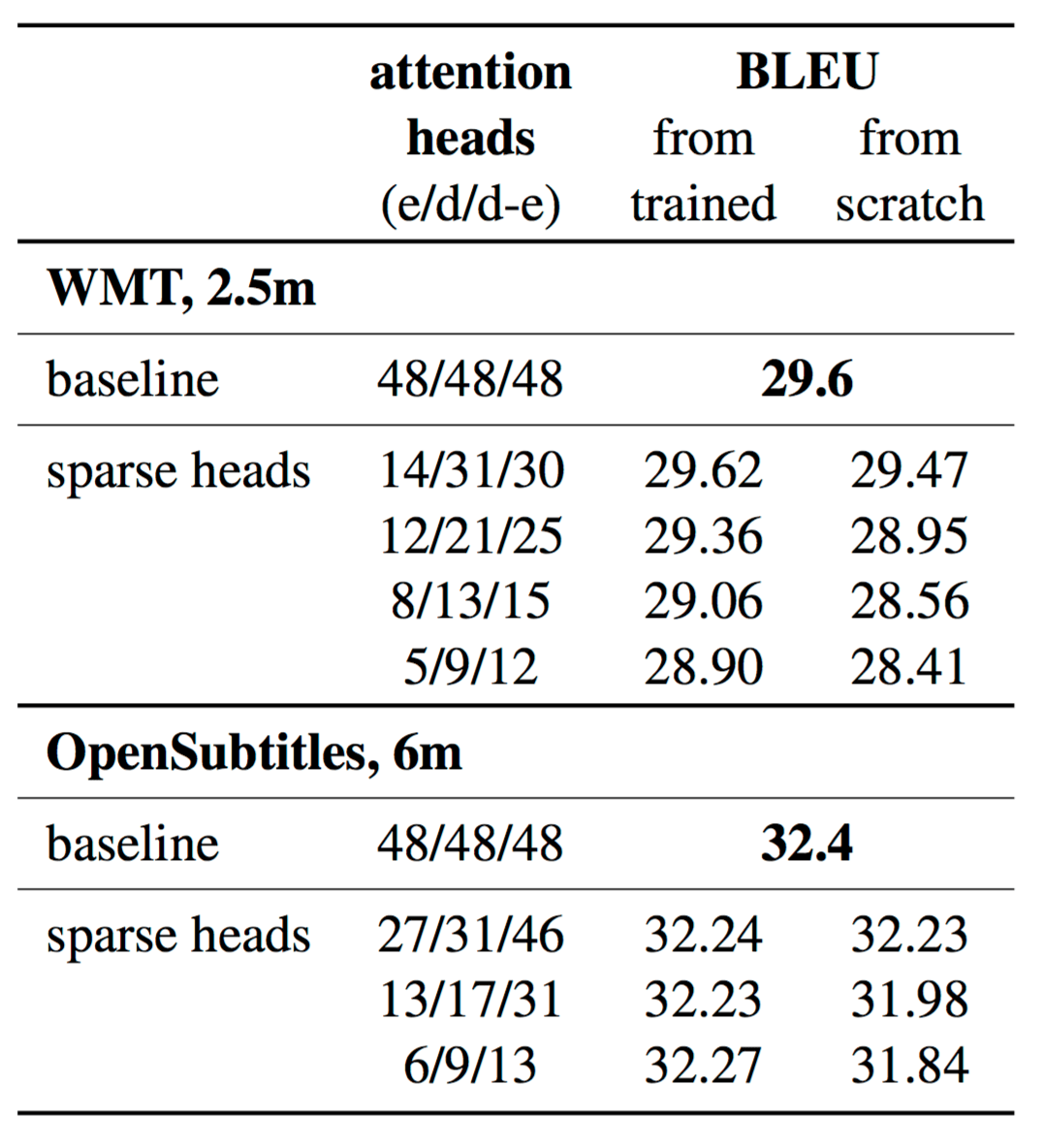 Results of experiments pruning heads in all attention layers are provided in table.
For all models, we can prune more than half of all attention heads and lose no more than 0.25 BLEU.
Results of experiments pruning heads in all attention layers are provided in table.
For all models, we can prune more than half of all attention heads and lose no more than 0.25 BLEU.
In the rightmost column we provide BLEU scores for models trained with exactly the same number and configuration of heads in each layer as the corresponding pruned models but starting from a random initialization of parameters. Here the degradation in translation quality is more significant than for pruned models with the same number of heads. This agrees with the observations made in model compression papers: sparse architectures learned through pruning cannot be trained from scratch to reach the same test set performance as a model trained with joint sparsification and optimization. See for example Zhu and Gupta, 2017 or Gale et al., 2019.
Pruning for analysis
Functions of retained encoder heads
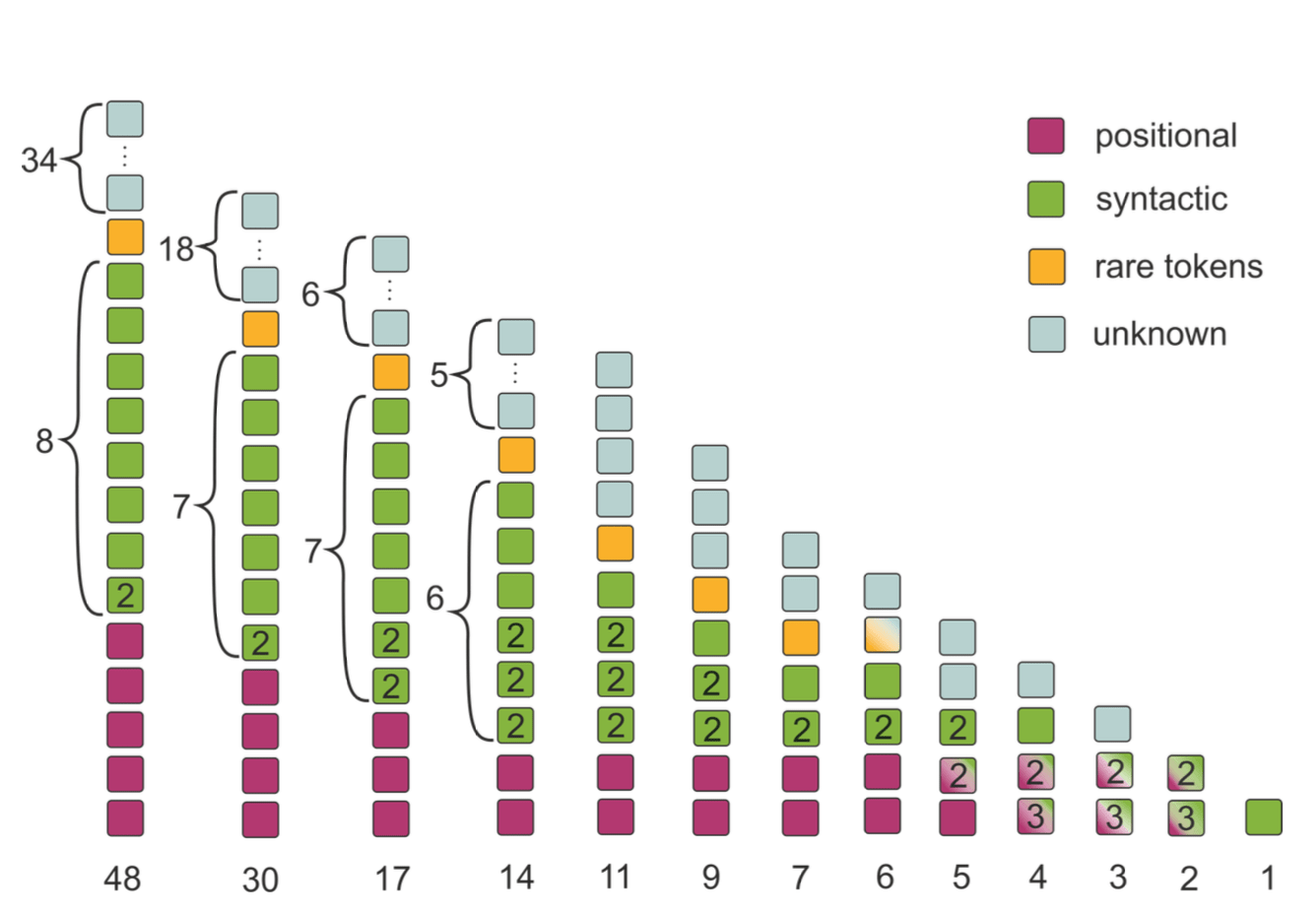
The figure shows functions of encoder heads retained after pruning. Each column represents all
remaining heads after varying amount of pruning; heads are color-coded for their function in a pruned model.
Some
heads can perform several functions (e.g., s → v and v → o); in this case the number of functions is shown.
Note that the model with 17 heads retains heads with all the functions that we identified previously, even though 2⁄3 of the heads have been pruned. This indicates that these functions are indeed the most important. Furthermore, when we have fewer heads in the model, some functions “drift” to other heads: for example, we see positional heads starting to track syntactic dependencies; hence some heads are assigned more than one color at certain stages.
Importance of attention types
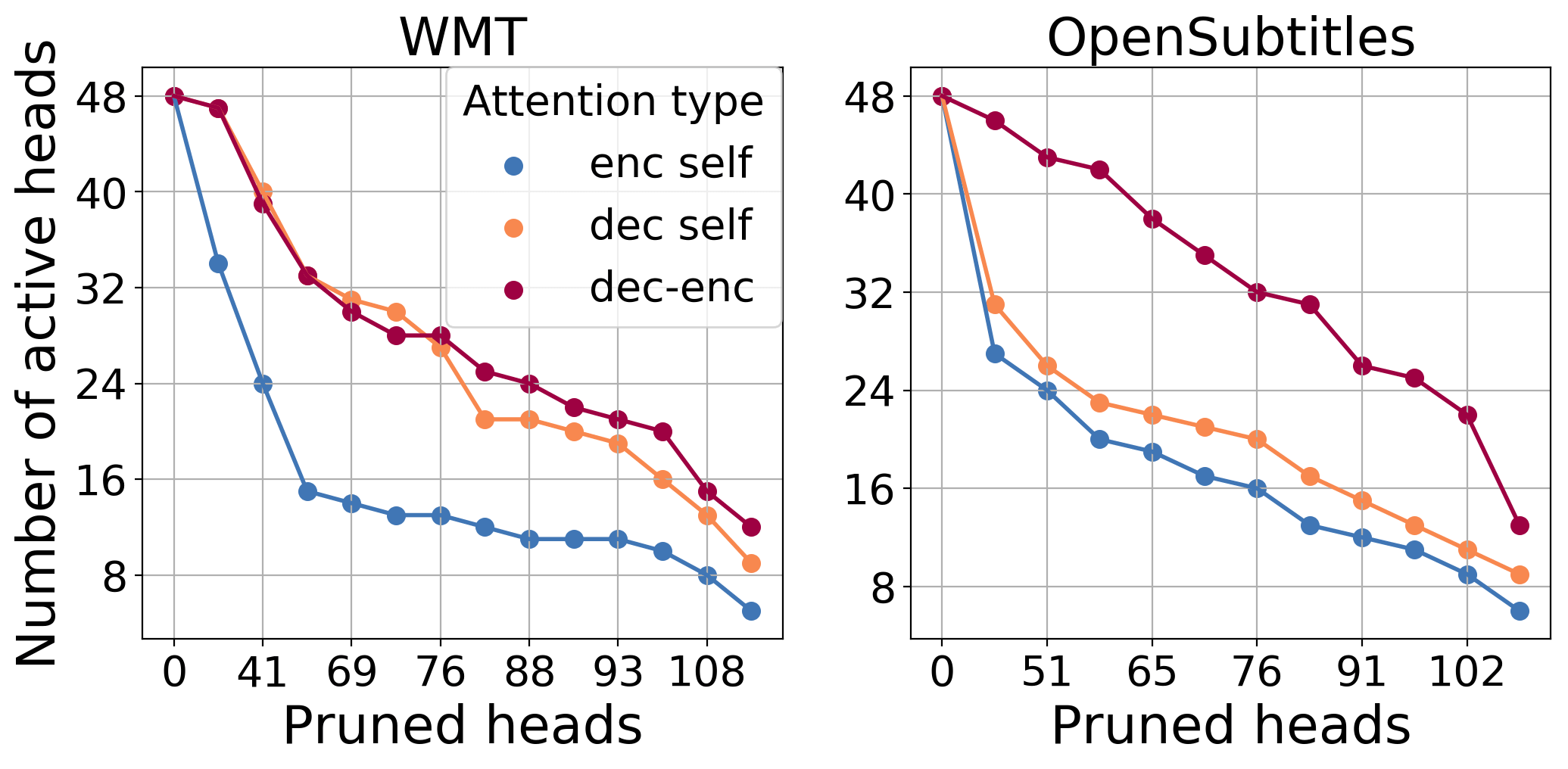 Here is shown the number of retained heads for each attention type at different pruning rates. We can see that the
model prefers to prune encoder self-attention heads first, while decoder-encoder attention heads appear to be the
most important for both datasets.
The importance of decoder self-attention heads, which function primarily as a target side language model,
varies across domains.
Here is shown the number of retained heads for each attention type at different pruning rates. We can see that the
model prefers to prune encoder self-attention heads first, while decoder-encoder attention heads appear to be the
most important for both datasets.
The importance of decoder self-attention heads, which function primarily as a target side language model,
varies across domains.
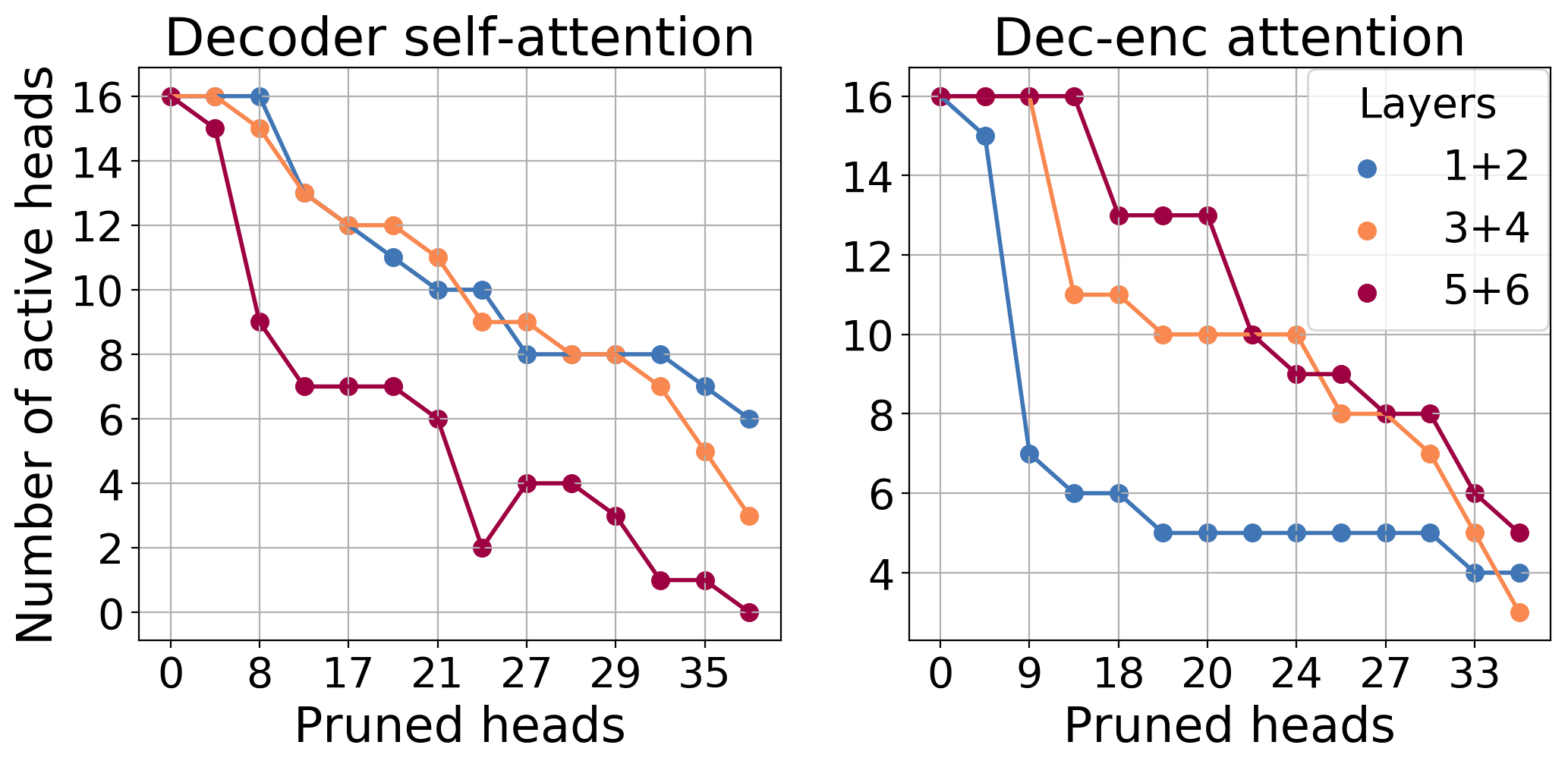 Here is shown the number of active self-attention and decoder-encoder attention heads at different layers
in the decoder for models with different sparsity rates (to reduce noise, we plot the sum of heads remaining
in pairs of adjacent layers). Self-attention heads are retained more readily in the lower
layers, while decoder-encoder attention heads are retained in the higher layers. This suggests that lower layers
of the Transformer’s decoder are mostly responsible for language modeling, while higher layers are mostly responsible
for conditioning on the source sentence.
Here is shown the number of active self-attention and decoder-encoder attention heads at different layers
in the decoder for models with different sparsity rates (to reduce noise, we plot the sum of heads remaining
in pairs of adjacent layers). Self-attention heads are retained more readily in the lower
layers, while decoder-encoder attention heads are retained in the higher layers. This suggests that lower layers
of the Transformer’s decoder are mostly responsible for language modeling, while higher layers are mostly responsible
for conditioning on the source sentence.
Conclusions
We evaluate the contribution made by individual attention heads to Transformer model performance on translation. We use layer-wise relevance propagation to show that the relative contribution of heads varies: only a small subset of heads appear to be important for the translation task. Important heads have one or more interpretable functions in the model, including attending to adjacent words and tracking specific syntactic relations. To determine if the remaining less-interpretable heads are crucial to the model’s performance, we introduce a new approach to pruning attention heads. We observe that specialized heads are the last to be pruned, confirming their importance directly. Moreover, the vast majority of heads, especially the encoder self-attention heads, can be removed without seriously affecting performance. In future work, we would like to investigate how our pruning method compares to alternative methods of model compression in NMT.P.S. There is also a recent study by Paul Michel, Omer Levy and Graham Neubig confirming our observations that importance of individual heads greatly varies. Have a look in their arXiv paper.
Want to know more?
Share: Tweet