NMT Training through the Lens of SMT
In SMT, model competences are modelled with distinct models. In NMT, the whole translation task is modelled with a single neural network. How and when does NMT get to learn all the competences? We show that
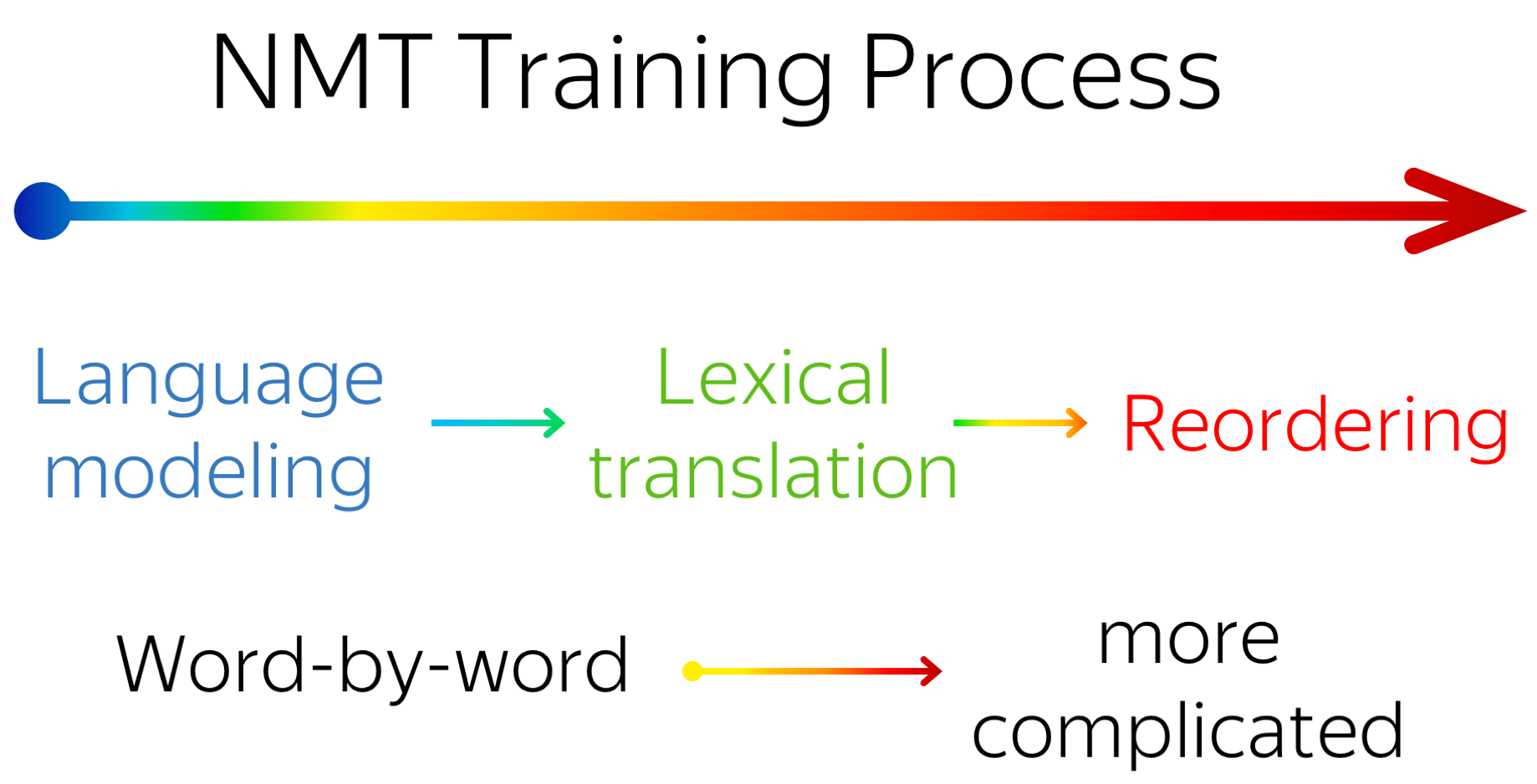
- during training, NMT undergoes three different stages:
- target-side language modeling,
- learning how to use source and approaching word-by-word translation,
- refining translations, visible by increasingly complex reorderings, but almost invisible to standard metrics (e.g. BLEU);
- not only this is fun, but it can also help in practice! For example, in settings where data complexity matters, such as non-autoregressive NMT.
 September 2021
September 2021
Machine Translation Task: Traditional vs Neural Mindsets
In the last couple of decades, the two main machine translation paradigms have been statistical and neural MT (SMT and NMT). Classical SMT splits the translation task into several components corresponding to the competences which researchers think the model should have. The typical components are: target-side language model, lexical translation model, and a reordering model. Overall, in SMT different competences are modelled with distinct model components which are trained separately and then put together in a translation model.
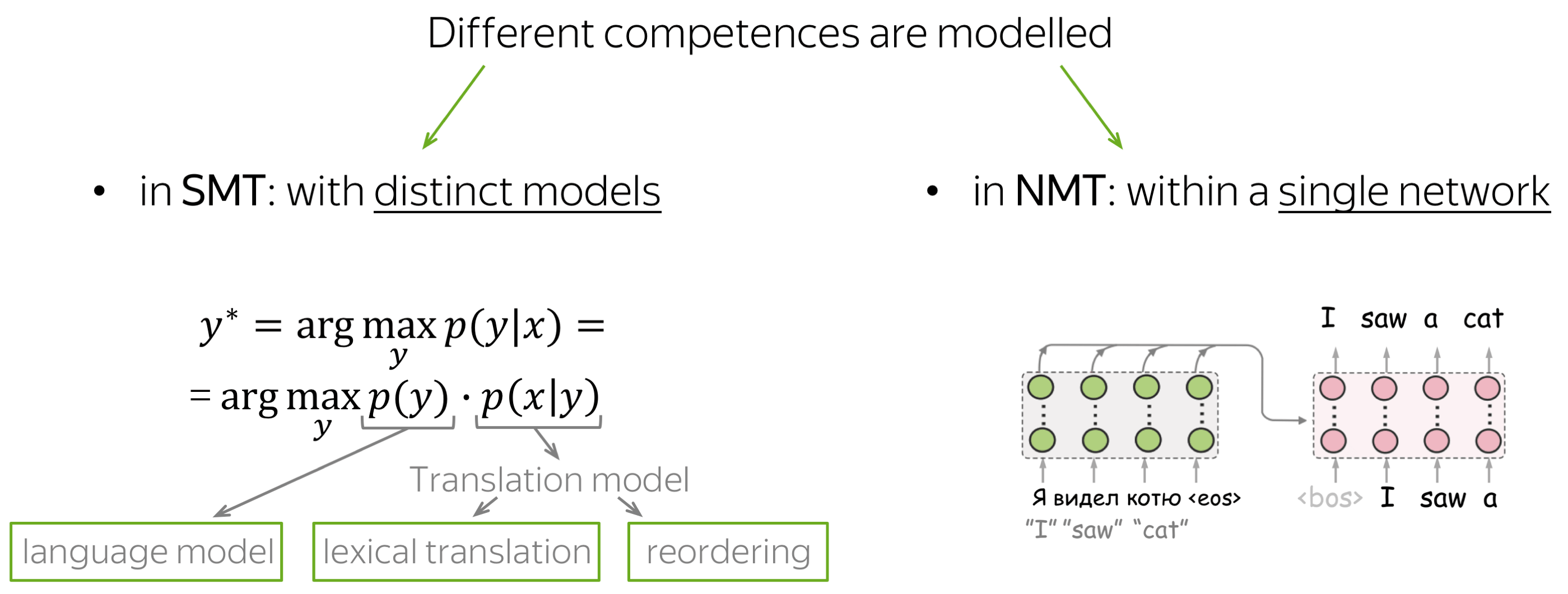

Differently, in NMT, the whole translation task is modelled with a single neural network. While NMT is the de-facto standard paradigm, it is still not clear how and when NMT acquires these competences during training.
For example, are there any stages where NMT focuses on fluency or adequacy, or does it improve everything at the same rate? Does it learn word-by-word translation first and more complicated patterns later, or is there a different behavior?
We know: NMT training has distinct stages
This is especially interesting in light of our ACL 2021 paper (here's the blog post!). There we looked at a model’s inner working (namely, how the predictions are formed) and we saw that the training process is non-monotonic, which means that there are stages with qualitatively different changes.

Differently, now we look at the model’s output and focus on the competences related to three core SMT components: target-side language modeling, lexical translation, and reordering.
We look at: LM scores, translation quality, monotonicity of alignments
For these competences, we evaluate language modeling scores, translation quality and monotonicity of alignments.

Target-Side Language Modeling
Let’s start with the language modeling scores. Here the x-axis shows the training step. We see that most of the change happens at the beginning of training. Also, the scores peak much higher than that of references (shown with the dashed line here). This means that the model probably generates very frequent n-grams rather than diverse texts similar to references.
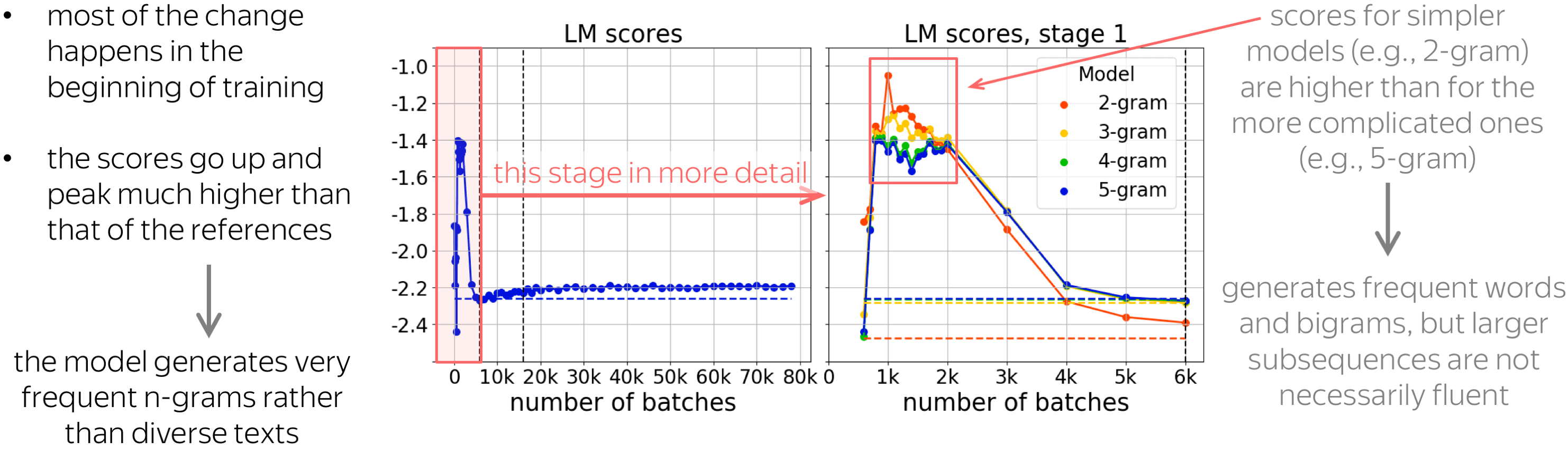
Let’s look at this early stage more closely and consider KenLM models with different context lengths: from bigram to 5-gram models. We see that for some part of training, scores for simpler models are higher than for the more complicated ones. For example, the 2-gram score is the highest and the 5-gram score is the lowest. This means that the model generates frequent words and n-grams, but larger subsequences are not necessarily fluent.
Below is an example of how a translation evolves at this early stage. This is English-German, our source sentence is six months of construction works, that’s brutal. On the left are model translations, and on the right is their approximate version in English.

We see that first, the model hallucinates the most frequent token, then bigram, the three-gram, then combinations of frequent phrases. After that, words related to the source start to appear, and only later we see something reasonable.
Translation Quality
Let’s now turn to translation quality. In addition to the BLEU score (which is the standard automatic evaluation metric for machine translation), we also show token-level accuracy for target tokens of different frequency ranks. Token-level accuracy is the proportion of cases where the correct next token is the most probable choice. Note that this is exactly what the model is trained to do: in a classification setting, it is trained to predict the next token.
We see that for rare tokens, accuracy improves slower than for the rest. This is expected: rare phenomena are learned later in training. What is not clear, is what happens during the last half of the training: changes in both BLEU and accuracy are almost invisible, even for rare tokens.
Monotonicity of Alignments
Luckily, we have one more thing to look at: monotonicity of alignments. The graph shows how the monotonicity of alignments changes during training. For more details on the metric, look at the paper, but everything we need to know now is that lower scores mean less monotonic (or more complicated) alignments in generated translations.
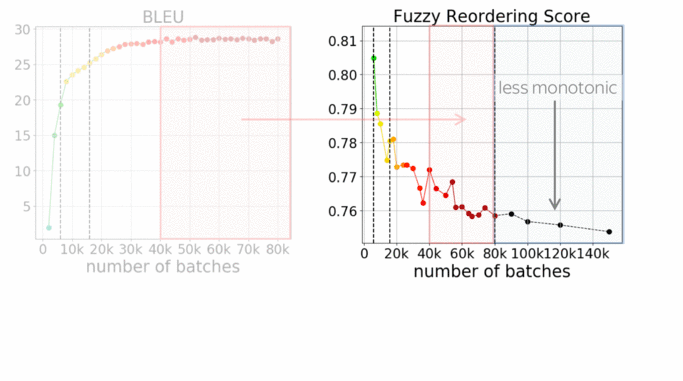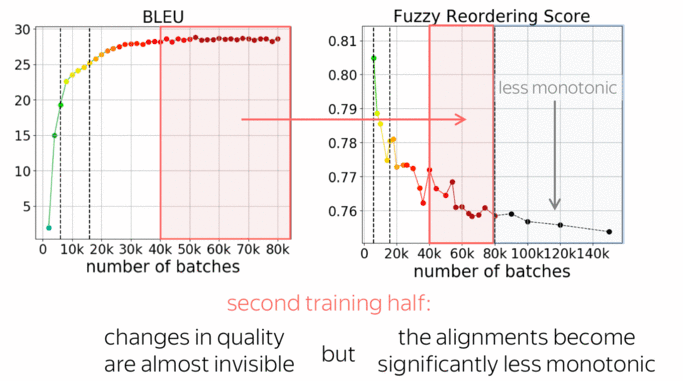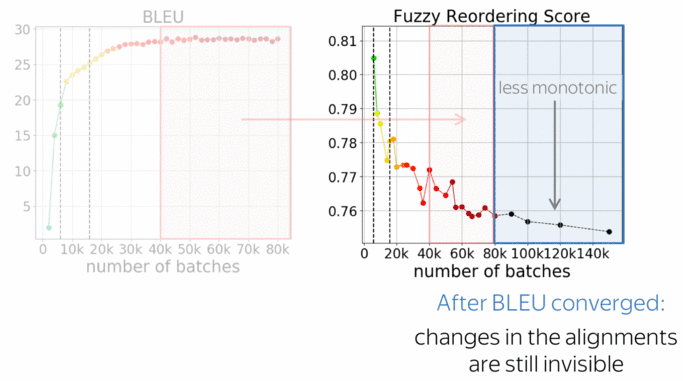
First, let's look again at the second half of the training we just looked at. While changes in quality are almost invisible, reorderings change significantly. In the absolute values this does not look like a lot, a bit later I’ll show you some examples and how this analysis can be used in practice to improve non-autoregressive NMT - you’ll see that these changes are quite prominent.
What is interesting, is that changes in the alignments are visible even after the model converges in terms of BLEU. This relates to one of our previous works on context-aware NMT (Voita et al, 2019): we observed that even after BLEU converges, discourse phenomena continue to improve.
Here are a couple of examples of how translations change during this last part of the training: the examples are for English-German and English-Russian, and same-colored chunks are approximately aligned to each other.

I don’t expect you to understand all the translations, but visually we can see that first, the translations are almost word-by-word, then the reordering becomes more complicated. For example, for English-Russian, the last phrase (shown in green) finally gets reordered to the beginning of the sentence. Note that the reorderings at these later training steps are more natural for the corresponding target language.
Characterizing Training Stages
Summarizing all the observations, we can say that NMT training undergoes three stages:
- target-side language modeling,
- learning how to use source and approaching word-by-word translation,
- refining translations, which is visible only by changes in the reordering and not visible by standard metrics.
Now let’s look at how these results agree with the stages we looked at in the ACL 2021 paper.
First, the source contribution goes down. Here the model relies on the target-side prefix and ignores the source, and looking at translations confirmed that here it learns language modeling. Then, the source contribution increases rapidly: the model starts to use the source, and we saw that the quality improves quickly. After these two stages, translations are close to word-by-word ones. Finally, where very little is going on, reorderings continue to become significantly more complicated.
Practical Applications of the Analysis
Finally, not only this is fun, but it can also be useful in practice. First, there are various settings where data complexity is important: therefore, translations from specific training stages can be useful. Next, there are a lot of SMT-inspired modeling modifications, and our analysis can help modeling modifications.


(using target-side language models, lexical tables, alignments, modeling phrases, etc.)
Links
Athur et al, 2016; He et al, 2016; Tang et al, 2016; Wang et al, 2017; Zhang et al, 2017a; Dahlmann et al, 2017; Gülçehre et al, 2015; Gülçehre et al, 2017; Stahlberg et al, 2018; Mi et al, 2016; Liu et al, 2016; Chen et al, 2016; Alkhouli et al, 2016; Alkhouli & Ney, 2017; Park & Tsvetkov, 2019; Song et al, 2020 among others
Non-Autoregressive Neural Machine Translation
We focus only on the first point, and as an example considers non-autoregressive NMT. For non-autoregressive models, it is standard to use sequence-level distillation. This means that targets for these models are not references but translations from an autoregressive teacher.
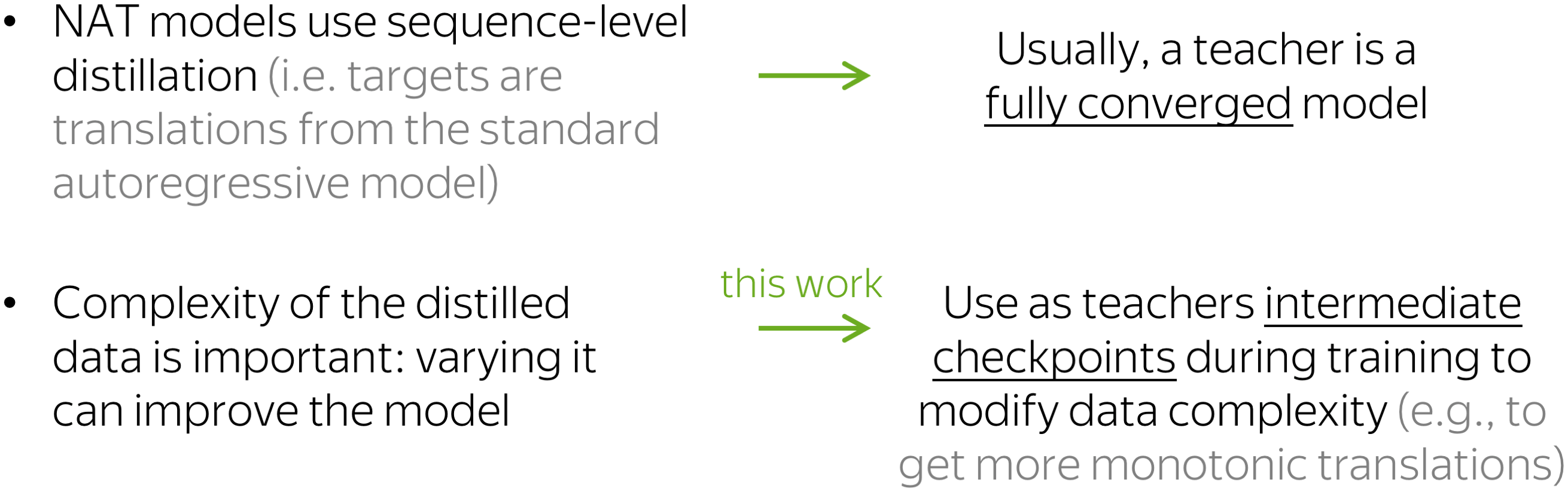
Previous work showed that complexity of the distilled data matters, and varying it can improve a model. While usually, a teacher is a fully converged model, we propose to use as teachers intermediate checkpoints during model’s training to get targets of varying complexity. For example, these earlier translations have more monotonic alignments.
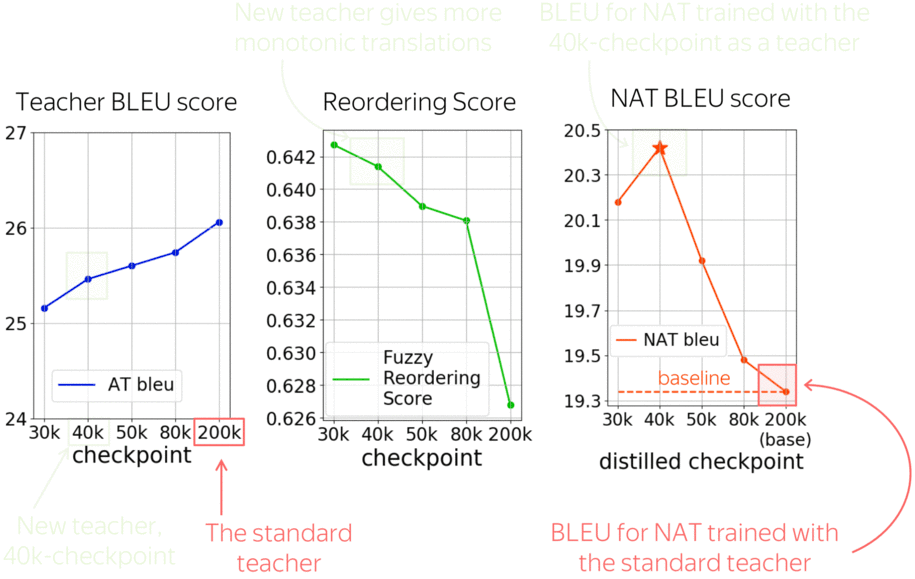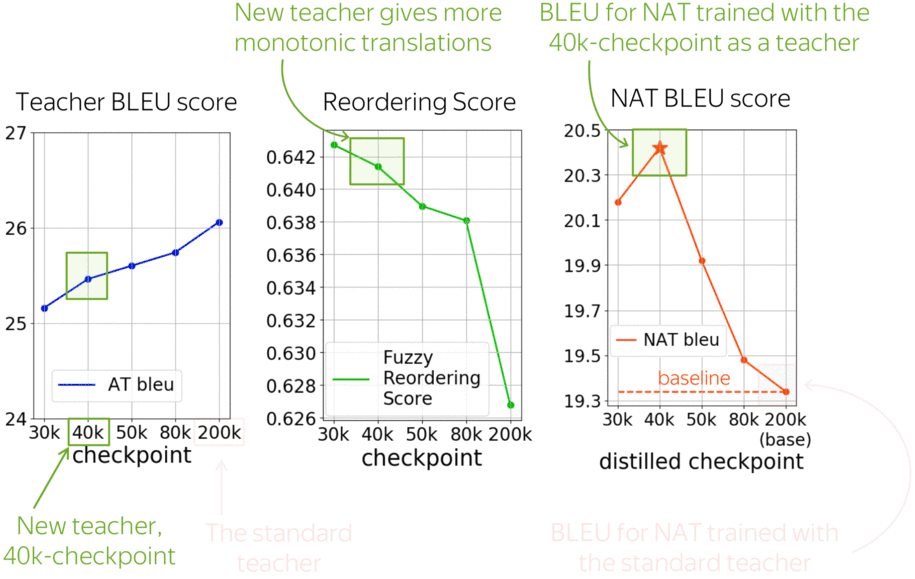
Let us look at a vanilla non-autoregressive model trained with different teachers. The standard teacher is the fully converged model, in this case after 200k training steps. But earlier checkpoints, for example after 40k-steps, have not much worse BLEU score, but significantly more monotonic alignments. And using these less trained teachers improves a vanilla NAT model by more than 1 bleu!
Conclusions:
- during training, NMT undergoes three different stages:
- target-side language modeling,
- learning how to use source and approaching word-by-word translation,
- refining translations, visible by increasingly complex reorderings, but almost invisible to standard metrics (e.g. BLEU);
- this is true not only for the standard encoder-decoder Transformer, but also for other models (e.g. LSTM) and modeling paradigms (e.g. LM-style NMT) - for this, see the paper;
- not only this is fun, but it can also help in practice! For example, in settings where data complexity matters, such as non-autoregressive NMT.
Share: Tweet